Tutorial 4: Interpretation Tutorial (requires GPU)
![]()
Official LightAutoML github repository is here
Some of HTML static content is not loading, to solve this problem you can use nbviewer. Link on tutorial on nbviewer here.
The last years deep neural networks / gradient boosting / ensembles of models allow to improve the soulution quality of many application task in field of natural language processing (NLP). The indicators of this improvement describe the partial behavior of the model and can hide errors, for example, errors in the construction of the model, errors in data collection. All this can be critical in tasks related to the processing of medical, forensic, banking data. In this tutorial we will check the NLP interpretation module of automl.
Download library and make some imports
[1]:
# !pip install lightautoml
[2]:
import shutil
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_score, mean_squared_error
from sklearn.model_selection import train_test_split
from lightautoml.automl.presets.text_presets import TabularNLPAutoML
from lightautoml.tasks import Task
from lightautoml.addons.interpretation import LimeTextExplainer, L2XTextExplainer
import transformers
transformers.logging.set_verbosity(50)
import pickle
Download data
For this tutorial we will use train dataset (train.csv) from Jigsaw-Toxic-Comment-Classification-Challage. The dataset contains textual comments and 6 attributes of this text (toxic, serve_toxic, obscene, treat, insult, identity_hate). For now, we will use only toxic attribute.
[3]:
# train.csv file from
# https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge/overview
data = pd.read_csv('train.csv')
data
[3]:
| id | comment_text | toxic | severe_toxic | obscene | threat | insult | identity_hate | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0000997932d777bf | Explanation\nWhy the edits made under my usern... | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 000103f0d9cfb60f | D'aww! He matches this background colour I'm s... | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 000113f07ec002fd | Hey man, I'm really not trying to edit war. It... | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0001b41b1c6bb37e | "\nMore\nI can't make any real suggestions on ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0001d958c54c6e35 | You, sir, are my hero. Any chance you remember... | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 159566 | ffe987279560d7ff | ":::::And for the second time of asking, when ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 159567 | ffea4adeee384e90 | You should be ashamed of yourself \n\nThat is ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 159568 | ffee36eab5c267c9 | Spitzer \n\nUmm, theres no actual article for ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 159569 | fff125370e4aaaf3 | And it looks like it was actually you who put ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 159570 | fff46fc426af1f9a | "\nAnd ... I really don't think you understand... | 0 | 0 | 0 | 0 | 0 | 0 |
159571 rows × 8 columns
Usage of AutoML
We will use standard lightautoml.automl.presets.text_presets.TabularNLPAutoML preset with finetuned TinyBERT from Hugging Face.
[4]:
np.random.seed(42)
train, test = train_test_split(data, test_size=0.2, random_state=42)
roles = {
'text': ['comment_text'],
'drop': ['id', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate'],
'target': 'toxic'
}
task = Task('binary')
automl = TabularNLPAutoML(
task=task,
timeout=3600,
cpu_limit=1,
gpu_ids='0',
general_params={
'nested_cv': False,
'use_algos': [['nn']]
},
autonlp_params={
'sent_scaler': 'l2'
},
text_params={
'lang': 'en',
'bert_model': 'prajjwal1/bert-tiny'
},
nn_params={
'opt_params': {'lr': 1e-5},
'max_length': 128,
'bs': 32,
'n_epochs': 7,
}
)
[5]:
%%time
oof_pred = automl.fit_predict(train, roles=roles, verbose = 10)
test_pred = automl.predict(test)
not_nan = np.any(~np.isnan(oof_pred.data), axis=1)
print('Check scores:')
print('OOF score: {}'.format(roc_auc_score(train[roles['target']].values[not_nan], oof_pred.data[not_nan][:, 0])))
print('TEST score: {}'.format(roc_auc_score(test[roles['target']].values, test_pred.data[:, 0])))
[11:22:30] Stdout logging level is DEBUG.
[11:22:30] Model language mode: en
[11:22:30] Task: binary
[11:22:30] Start automl preset with listed constraints:
[11:22:30] - time: 3600.00 seconds
[11:22:30] - CPU: 1 cores
[11:22:30] - memory: 16 GB
[11:22:30] Train data shape: (127656, 8)
[11:22:30] Layer 1 train process start. Time left 3599.85 secs
[11:22:31] Start fitting Lvl_0_Pipe_0_Mod_0_TorchNN ...
[11:22:31] Training params: {'bs': 32, 'num_workers': 1, 'max_length': 128, 'opt_params': {'lr': 1e-05}, 'scheduler_params': {'patience': 5, 'factor': 0.5, 'verbose': True}, 'is_snap': False, 'snap_params': {'k': 1, 'early_stopping': True, 'patience': 1, 'swa': False}, 'init_bias': True, 'n_epochs': 7, 'input_bn': False, 'emb_dropout': 0.1, 'emb_ratio': 3, 'max_emb_size': 50, 'bert_name': 'prajjwal1/bert-tiny', 'pooling': 'cls', 'device': device(type='cuda', index=0), 'use_cont': True, 'use_cat': True, 'use_text': True, 'lang': 'en', 'deterministic': False, 'multigpu': False, 'random_state': 42, 'path_to_save': None, 'verbose_inside': None, 'verbose': 1, 'device_ids': None, 'n_out': 1, 'cat_features': [], 'cat_dims': [], 'cont_features': [], 'cont_dim': 0, 'text_features': ['concated__comment_text'], 'bias': array([[-2.24401446]])}
[11:22:31] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_TorchNN =====
[11:22:36] number of text features: 1
[11:22:36] number of categorical features: 0
[11:22:36] number of continuous features: 0
train (loss=0.257356): 100%|██████████| 2660/2660 [02:12<00:00, 20.13it/s]
val: 100%|██████████| 1330/1330 [01:07<00:00, 19.83it/s]
[11:25:59] Epoch: 0, train loss: 0.25735557079315186, val loss: 0.19599375128746033, val metric: 0.9640350800072578
train (loss=0.168968): 100%|██████████| 2660/2660 [02:09<00:00, 20.61it/s]
val: 100%|██████████| 1330/1330 [01:04<00:00, 20.58it/s]
[11:29:13] Epoch: 1, train loss: 0.16896754503250122, val loss: 0.14401142299175262, val metric: 0.9713461808486132
train (loss=0.131891): 100%|██████████| 2660/2660 [02:09<00:00, 20.49it/s]
val: 100%|██████████| 1330/1330 [01:03<00:00, 20.87it/s]
[11:32:26] Epoch: 2, train loss: 0.1318911910057068, val loss: 0.12361849099397659, val metric: 0.9742718921629787
train (loss=0.114705): 100%|██████████| 2660/2660 [02:07<00:00, 20.90it/s]
val: 100%|██████████| 1330/1330 [01:04<00:00, 20.76it/s]
[11:35:38] Epoch: 3, train loss: 0.11470535397529602, val loss: 0.11394938081502914, val metric: 0.9763582643756192
train (loss=0.103179): 100%|██████████| 2660/2660 [02:09<00:00, 20.54it/s]
val: 100%|██████████| 1330/1330 [01:05<00:00, 20.36it/s]
[11:38:53] Epoch: 4, train loss: 0.10317856818437576, val loss: 0.10656153410673141, val metric: 0.9775081138714583
train (loss=0.0965996): 100%|██████████| 2660/2660 [02:09<00:00, 20.49it/s]
val: 100%|██████████| 1330/1330 [01:05<00:00, 20.24it/s]
[11:42:08] Epoch: 5, train loss: 0.09659960865974426, val loss: 0.10427780449390411, val metric: 0.9783243683208365
train (loss=0.090561): 100%|██████████| 2660/2660 [02:11<00:00, 20.24it/s]
val: 100%|██████████| 1330/1330 [01:02<00:00, 21.23it/s]
[11:45:22] Epoch: 6, train loss: 0.09056100249290466, val loss: 0.10337436944246292, val metric: 0.9788043902058639
[11:45:23] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_TorchNN =====
[11:45:28] number of text features: 1
[11:45:28] number of categorical features: 0
[11:45:28] number of continuous features: 0
train (loss=0.257485): 100%|██████████| 2660/2660 [02:04<00:00, 21.30it/s]
val: 100%|██████████| 1330/1330 [01:04<00:00, 20.67it/s]
[11:48:38] Epoch: 0, train loss: 0.2574850618839264, val loss: 0.19478833675384521, val metric: 0.961936968917119
train (loss=0.170552): 100%|██████████| 2660/2660 [02:08<00:00, 20.72it/s]
val: 100%|██████████| 1330/1330 [01:06<00:00, 19.87it/s]
[11:51:53] Epoch: 1, train loss: 0.1705523431301117, val loss: 0.1437842845916748, val metric: 0.970873732336761
train (loss=0.132485): 100%|██████████| 2660/2660 [02:05<00:00, 21.15it/s]
val: 100%|██████████| 1330/1330 [01:03<00:00, 20.97it/s]
[11:55:03] Epoch: 2, train loss: 0.13248467445373535, val loss: 0.12127983570098877, val metric: 0.9751468710522353
train (loss=0.11448): 100%|██████████| 2660/2660 [02:03<00:00, 21.51it/s]
val: 100%|██████████| 1330/1330 [01:02<00:00, 21.11it/s]
[11:58:09] Epoch: 3, train loss: 0.11447965353727341, val loss: 0.11149459332227707, val metric: 0.9768346789459879
train (loss=0.103458): 100%|██████████| 2660/2660 [02:06<00:00, 20.99it/s]
val: 100%|██████████| 1330/1330 [01:04<00:00, 20.65it/s]
[12:01:20] Epoch: 4, train loss: 0.10345754027366638, val loss: 0.10722416639328003, val metric: 0.9782435623593337
train (loss=0.0963441): 100%|██████████| 2660/2660 [02:05<00:00, 21.17it/s]
val: 100%|██████████| 1330/1330 [01:03<00:00, 20.91it/s]
[12:04:30] Epoch: 5, train loss: 0.09634406119585037, val loss: 0.10441421717405319, val metric: 0.978748563376753
train (loss=0.0900231): 100%|██████████| 2660/2660 [02:05<00:00, 21.17it/s]
val: 100%|██████████| 1330/1330 [01:03<00:00, 20.84it/s]
[12:07:39] Epoch: 6, train loss: 0.09002314507961273, val loss: 0.10312184691429138, val metric: 0.9791290354336872
[12:07:40] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_TorchNN =====
[12:07:44] number of text features: 1
[12:07:44] number of categorical features: 0
[12:07:44] number of continuous features: 0
train (loss=0.257448): 100%|██████████| 2660/2660 [02:04<00:00, 21.45it/s]
val: 100%|██████████| 1330/1330 [01:00<00:00, 21.91it/s]
[12:10:50] Epoch: 0, train loss: 0.2574479281902313, val loss: 0.19449889659881592, val metric: 0.9648288318293945
train (loss=0.169502): 100%|██████████| 2660/2660 [02:03<00:00, 21.52it/s]
val: 100%|██████████| 1330/1330 [01:01<00:00, 21.79it/s]
[12:13:55] Epoch: 1, train loss: 0.1695016324520111, val loss: 0.14307956397533417, val metric: 0.9706200035841146
train (loss=0.131626): 100%|██████████| 2660/2660 [02:03<00:00, 21.54it/s]
val: 100%|██████████| 1330/1330 [01:00<00:00, 21.84it/s]
[12:16:59] Epoch: 2, train loss: 0.13162554800510406, val loss: 0.12111066281795502, val metric: 0.97454294780979
train (loss=0.114015): 100%|██████████| 2660/2660 [02:03<00:00, 21.57it/s]
val: 100%|██████████| 1330/1330 [01:00<00:00, 21.83it/s]
[12:20:04] Epoch: 3, train loss: 0.11401509493589401, val loss: 0.11131983995437622, val metric: 0.9763178957078734
train (loss=0.104155): 100%|██████████| 2660/2660 [02:03<00:00, 21.56it/s]
val: 100%|██████████| 1330/1330 [01:00<00:00, 21.87it/s]
[12:23:08] Epoch: 4, train loss: 0.10415521264076233, val loss: 0.10691472887992859, val metric: 0.9772204526836245
train (loss=0.0953203): 100%|██████████| 2660/2660 [02:04<00:00, 21.41it/s]
val: 100%|██████████| 1330/1330 [01:01<00:00, 21.67it/s]
[12:26:13] Epoch: 5, train loss: 0.09532025456428528, val loss: 0.10362745076417923, val metric: 0.9780747656394276
train (loss=0.0899258): 100%|██████████| 2660/2660 [02:04<00:00, 21.34it/s]
val: 100%|██████████| 1330/1330 [01:01<00:00, 21.68it/s]
[12:29:20] Epoch: 6, train loss: 0.08992581069469452, val loss: 0.10427321493625641, val metric: 0.9781931517871759
val: 100%|██████████| 1330/1330 [01:01<00:00, 21.53it/s]
[12:30:21] Early stopping: val loss: 0.10362745076417923, val metric: 0.9780747656394276
[12:30:22] Fitting Lvl_0_Pipe_0_Mod_0_TorchNN finished. score = 0.9782371823652668
[12:30:22] Lvl_0_Pipe_0_Mod_0_TorchNN fitting and predicting completed
[12:30:22] Time left -472.15 secs
[12:30:22] Time limit exceeded. Last level models will be blended and unused pipelines will be pruned.
[12:30:22] Layer 1 training completed.
[12:30:22] Automl preset training completed in 4072.15 seconds
[12:30:22] Model description:
Final prediction for new objects (level 0) =
1.00000 * (3 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN)
[12:30:22] number of text features: 1
[12:30:22] number of categorical features: 0
[12:30:22] number of continuous features: 0
test: 100%|██████████| 998/998 [00:47<00:00, 21.08it/s]
[12:31:15] number of text features: 1
[12:31:15] number of categorical features: 0
[12:31:15] number of continuous features: 0
test: 100%|██████████| 998/998 [00:46<00:00, 21.51it/s]
[12:32:08] number of text features: 1
[12:32:08] number of categorical features: 0
[12:32:08] number of continuous features: 0
test: 100%|██████████| 998/998 [00:46<00:00, 21.47it/s]
Check scores:
OOF score: 0.9782371823652668
TEST score: 0.9807740353486142
CPU times: user 18min 47s, sys: 1min 15s, total: 20min 3s
Wall time: 1h 10min 30s
[6]:
automl.set_verbosity_level(0) # refuse logging in automl
LIME
Linear approximation of model nearby selected object. The weights of this linear model is feature attribution for automl’s prediction for this object.
Algorithm:
Select object to interpret.
Select the input text column, that will be explained (
perturb_column). All other columns of object will be fixed.A dataset of size
n_sample(by default5000) is created by randomly deleting tokens (in groups). Dataset is binary (there is a token if one and no token if zero).Predict with AutoML module target values for created dataset.
Optionally, the selection of features (important tokens) is performed using LASSO (
feature_selection='lasso', you can also'none'to not select and get them all). The number of features used after feature selection isn_feautres(= 10by default).We train the explained model on this (a linear model with weights, the method of calculating weights is the cosine distance by default, you can also use your own function or the name of the distance from
sklearn.metrics.pairwise_distances).The weights of the linear model are the interpretation.
P.S. Care about the sentence length. Detokenization works within \(O(n^2)\), where \(n\) – sentence length.
Scheme of work:
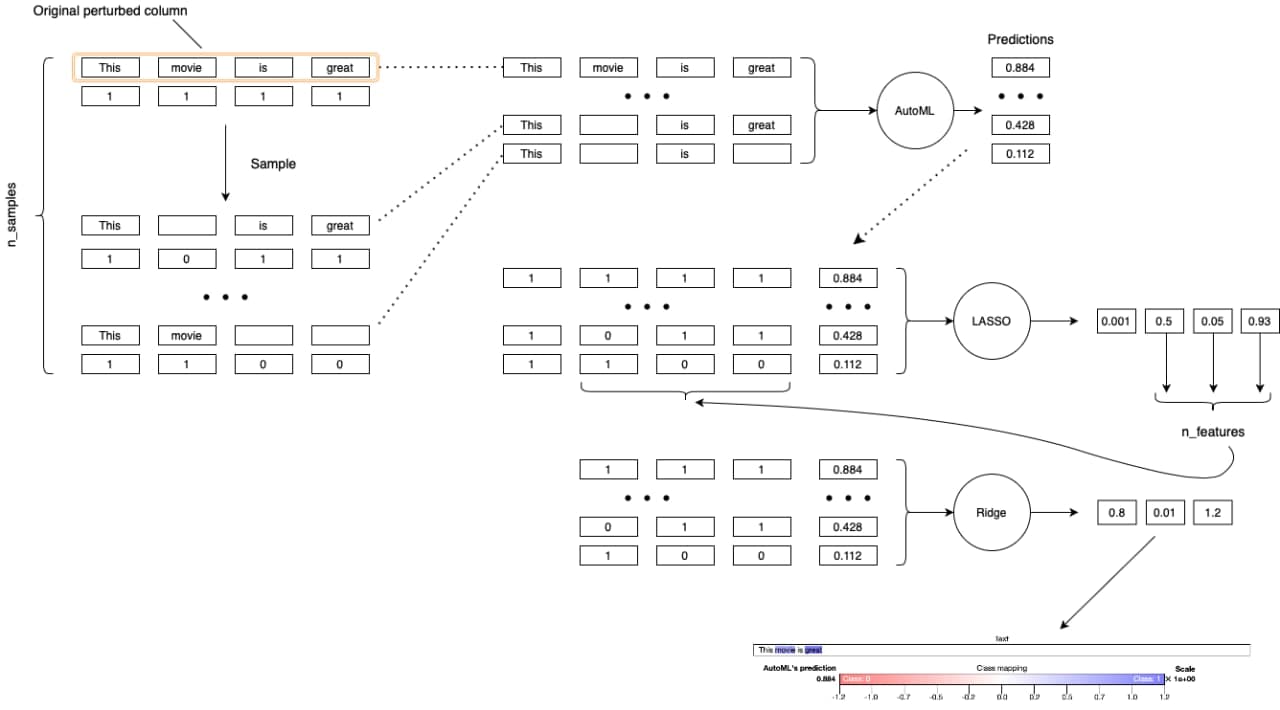
[7]:
# LimeTextExplainer for NLP preset
lime = LimeTextExplainer(automl, feature_selection='lasso', force_order=False)
Let’s try it on neutral text
[8]:
exp = lime.explain_instance(test.loc[34019], labels=(0, 1), perturb_column='comment_text')
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 77.34it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 79.52it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 78.82it/s]
Text
The lyrics is found in the German version , so I assume it ' s usable . ~
Class mapping
Class: 0 Class: 1
Toxic comments
[9]:
exp = lime.explain_instance(test.loc[78687], labels=(0, 1), perturb_column='comment_text')
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:01<00:00, 93.42it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 92.47it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 93.75it/s]
Text
A silly fat cow who won ' t leave me alone
Class mapping
Class: 0 Class: 1
Let’s see on uncertain expamples
[10]:
exp = lime.explain_instance(test.loc[4733], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 71.46it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 71.48it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 71.15it/s]
Text
Why are you still here ? Can you not find anything more important to do , like killing yourself ?
Class mapping
Class: 0 Class: 1
Let’s delete ‘important’ from this abstract. We can see that automl increase it’s probability of toxicity of this abstract
[11]:
test.loc[4733, 'comment_text'] = 'Why are you still here ? Can you not find anything more to do , like killing yourself ?'
[12]:
exp = lime.explain_instance(test.loc[4733], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 73.97it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 73.07it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 73.22it/s]
Text
Why are you still here ? Can you not find anything more to do , like killing yourself ?
Class mapping
Class: 0 Class: 1
If we add the ‘relability’ the AutoML decrease the toxicity probability.
[13]:
test.loc[4733, 'comment_text'] = 'Why are you still here ? Can you not find anything more to do , like killing yourself ? relability'
[14]:
exp = lime.explain_instance(test.loc[4733], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 68.66it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 64.12it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 68.18it/s]
Text
Why are you still here ? Can you not find anything more to do , like killing yourself ? relability
Class mapping
Class: 0 Class: 1
Another example
[15]:
exp = lime.explain_instance(test.loc[40112], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 57.57it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 56.72it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 56.36it/s]
Text
stop editing this , you dumbass . why do you have to be such a bitch ? the ghosts of bill maas ' past will haunt you forever !!! MWAHAHHAHAA
Class mapping
Class: 0 Class: 1
Let’s delete the toxic words to ‘good boy’
[16]:
test.loc[40112, 'comment_text'] = "stop editing this, you good boy. why do you have to be such a good boy? the ghosts of bill maas' past will haunt you forever!!! MWAHAHHAHAA"
[17]:
exp = lime.explain_instance(test.loc[40112], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 55.40it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 56.35it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 55.86it/s]
Text
stop editing this , you good boy . why do you have to be such a good boy ? the ghosts of bill maas ' past will haunt you forever !!! MWAHAHHAHAA
Class mapping
Class: 0 Class: 1
Let’s try from neutral make toxic abstract.
[18]:
exp = lime.explain_instance(test.loc[18396], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:01<00:00, 101.90it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 100.88it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 99.18it/s]
Text
Okay , thanks . I will do so .
Class mapping
Class: 0 Class: 1
[19]:
test.loc[18396] = "Okay , thanks . I will do so . dumbass please"
[20]:
exp = lime.explain_instance(test.loc[18396], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:01<00:00, 89.68it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 90.71it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 90.35it/s]
Text
Okay , thanks . I will do so . dumbass please
Class mapping
Class: 0 Class: 1
Adding some happy words
[21]:
test.loc[18396] = "Okay , thanks . I will do so . happy dumbass please"
[22]:
exp = lime.explain_instance(test.loc[18396], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:01<00:00, 86.02it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 87.59it/s]
test: 100%|██████████| 157/157 [00:01<00:00, 85.69it/s]
Text
Okay , thanks . I will do so . happy dumbass please
Class mapping
Class: 0 Class: 1
More happy words.
[23]:
test.loc[18396] = "Okay , thanks . I will do so . happy cheerful joyfull glorious elated dumbass please"
[24]:
exp = lime.explain_instance(test.loc[18396], labels=(0, 1), perturb_column='comment_text', n_features=20)
exp.visualize_in_notebook(1)
test: 100%|██████████| 157/157 [00:02<00:00, 75.00it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 74.62it/s]
test: 100%|██████████| 157/157 [00:02<00:00, 74.52it/s]
Text
Okay , thanks . I will do so . happy cheerful joyfull glorious elated dumbass please
Class mapping
Class: 0 Class: 1
L2X for Regression
For this part the BeerAdvocate we will use. The dataset contains the reviews on alcoholic drinks (texutal comment + 5 attributes: overview, taste, plate, aroma, appearance). For this experiment we will use only appearance attribute.
[25]:
def download_from_gdrive(file_id, file_name, chunk_size=2**15):
import requests
def handle_warning(res):
for k, v in res.cookies.items():
if k.startswith("download_warning"):
return v
template_url = "https://docs.google.com/uc?export=download"
session = requests.Session()
res = session.get(template_url, params={"id": file_id}, stream=True)
print('GET: {} CODE'.format(res.status_code))
token = handle_warning(res)
if token:
res = session.get(template_url, params={"id": file_id, "confirm": token}, stream=True)
print('Started downloading...')
with open(file_name, 'wb') as f:
for chunk in res.iter_content(chunk_size):
if chunk:
f.write(chunk)
print('Downloaded.')
download_from_gdrive('1s8PG13Y0BvYM67nNL0EQpdgB5S4gJK9r', 'beeradvocate.tar.gz')
shutil.unpack_archive('beeradvocate.tar.gz', '.')
GET: 200 CODE
Started downloading...
Downloaded.
[26]:
train_data = pd.read_csv('./datasets/reviews.aspect0.train.csv')
valid_data = pd.read_csv('./datasets/reviews.aspect0.heldout.csv')
train_data.head()
[26]:
| Appearance | Aroma | Palate | Taste | Overall | Review | tokens_number | |
|---|---|---|---|---|---|---|---|
| 0 | 1.5 | 1.5 | 2.5 | 1.5 | 1.5 | the main problem with this beer is that it has... | 62 |
| 1 | 2.0 | 2.0 | 3.0 | 2.0 | 3.0 | it is very unfortunate this situation we have ... | 179 |
| 2 | 4.0 | 2.5 | 3.0 | 1.5 | 2.0 | appearance is a light golden yellow with a thi... | 79 |
| 3 | 4.5 | 3.5 | 2.0 | 3.5 | 3.0 | it has a great color to the body . this beer p... | 87 |
| 4 | 4.0 | 4.5 | 1.0 | 1.5 | 1.0 | though this beer is , or course , not carbonat... | 246 |
Train AutoML
In this part we use BERT-Base model.
[27]:
roles = {
'text': ['Review'],
'drop': ['tokens_number', 'Aroma', 'Palete', 'Taste', 'Overall'],
'target': 'Appearance'
}
task = Task('reg')
automl = TabularNLPAutoML(
task=task,
timeout=3600,
cpu_limit=1,
gpu_ids='1',
general_params={
'nested_cv': False,
'use_algos': [['nn']],
'n_folds': 3
},
reader_params={
'cv': 3
},
autonlp_params={
'sent_scaler': 'l2'
},
text_params={
'lang': 'en',
'bert_model': 'bert-base-uncased'
},
nn_params={
'opt_params': {'lr': 1e-5},
'max_length': 128,
'bs': 32,
'n_epochs': 7,
},
)
oof_pred = automl.fit_predict(train_data, roles=roles, verbose=2)
test_pred = automl.predict(valid_data)
not_nan = np.any(~np.isnan(oof_pred.data), axis=1)
print('Check scores:')
print('OOF score: {}'.format(mean_squared_error(train_data[roles['target']].values[not_nan], oof_pred.data[not_nan][:, 0])))
print('TEST score: {}'.format(mean_squared_error(valid_data[roles['target']].values, test_pred.data[:, 0])))
[12:38:00] Stdout logging level is INFO2.
[12:38:00] Task: reg
[12:38:00] Start automl preset with listed constraints:
[12:38:00] - time: 3600.00 seconds
[12:38:00] - CPU: 1 cores
[12:38:00] - memory: 16 GB
[12:38:00] Train data shape: (80000, 7)
[12:38:01] Layer 1 train process start. Time left 3599.63 secs
[12:38:01] Start fitting Lvl_0_Pipe_0_Mod_0_TorchNN ...
[12:38:01] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_TorchNN =====
train (loss=0.755747): 100%|██████████| 1667/1667 [06:45<00:00, 4.11it/s]
val: 100%|██████████| 834/834 [02:04<00:00, 6.68it/s]
train (loss=0.442306): 100%|██████████| 1667/1667 [06:48<00:00, 4.08it/s]
val: 100%|██████████| 834/834 [02:05<00:00, 6.66it/s]
train (loss=0.344638): 100%|██████████| 1667/1667 [06:52<00:00, 4.04it/s]
val: 100%|██████████| 834/834 [02:06<00:00, 6.61it/s]
val: 100%|██████████| 834/834 [02:05<00:00, 6.64it/s]
[13:07:23] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_TorchNN =====
train (loss=0.760973): 100%|██████████| 1667/1667 [06:51<00:00, 4.05it/s]
val: 100%|██████████| 834/834 [02:06<00:00, 6.62it/s]
train (loss=0.44357): 100%|██████████| 1667/1667 [06:50<00:00, 4.06it/s]
val: 100%|██████████| 834/834 [02:06<00:00, 6.61it/s]
train (loss=0.343338): 100%|██████████| 1667/1667 [06:49<00:00, 4.07it/s]
val: 100%|██████████| 834/834 [02:05<00:00, 6.66it/s]
val: 100%|██████████| 834/834 [02:05<00:00, 6.66it/s]
[13:36:29] Time limit exceeded after calculating fold 1
[13:36:29] Fitting Lvl_0_Pipe_0_Mod_0_TorchNN finished. score = -0.46728458911890136
[13:36:29] Lvl_0_Pipe_0_Mod_0_TorchNN fitting and predicting completed
[13:36:29] Time left 91.29 secs
[13:36:29] Time limit exceeded in one of the tasks. AutoML will blend level 1 models.
[13:36:29] Layer 1 training completed.
[13:36:29] Automl preset training completed in 3508.71 seconds
[13:36:29] Model description:
Final prediction for new objects (level 0) =
1.00000 * (2 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN)
test: 100%|██████████| 313/313 [00:47<00:00, 6.63it/s]
test: 100%|██████████| 313/313 [00:47<00:00, 6.64it/s]
Check scores:
OOF score: 0.46728458911890136
TEST score: 0.43322843977913716
[28]:
# >>> about 2gb
with open('apperance_model.pkl', 'wb') as f:
pickle.dump(automl, f)
[29]:
with open('apperance_model.pkl', 'rb') as f:
automl = pickle.load(f)
automl.set_verbosity_level(2)
[13:38:29] Stdout logging level is INFO2.
L2X
Algorithm.
The general idea of method is find the most informative subset of tokens with respect to target using Mutual Information. The number of tokens in this subset is fixed and equals
n_important.There is may be some misunderstanding with tokenization that used inside models in automl and tokenization in this method. L2X has its own tokenization, so they are different. If it isn’t set we infer it from default tokenization for language in
text_paramsofTabularNLPAutoML. Else you can set it with language:'ru'or'en'for russian and english languages, respectively. Also it can be scepcified as callable function that from string produces list of tokens.After tokenization sentence was presented as the matrix of embedding vectors (you can specify
embedderor randomly initialized embeddings will be used). Not important vectors of this matrix will be masked (important tokens selected with Token Importance + Subset Sampler blocks), and the other use for model (Distil model), that tries to imitate the original automl model (learns to predict the same outputs).Scheme of L2X:
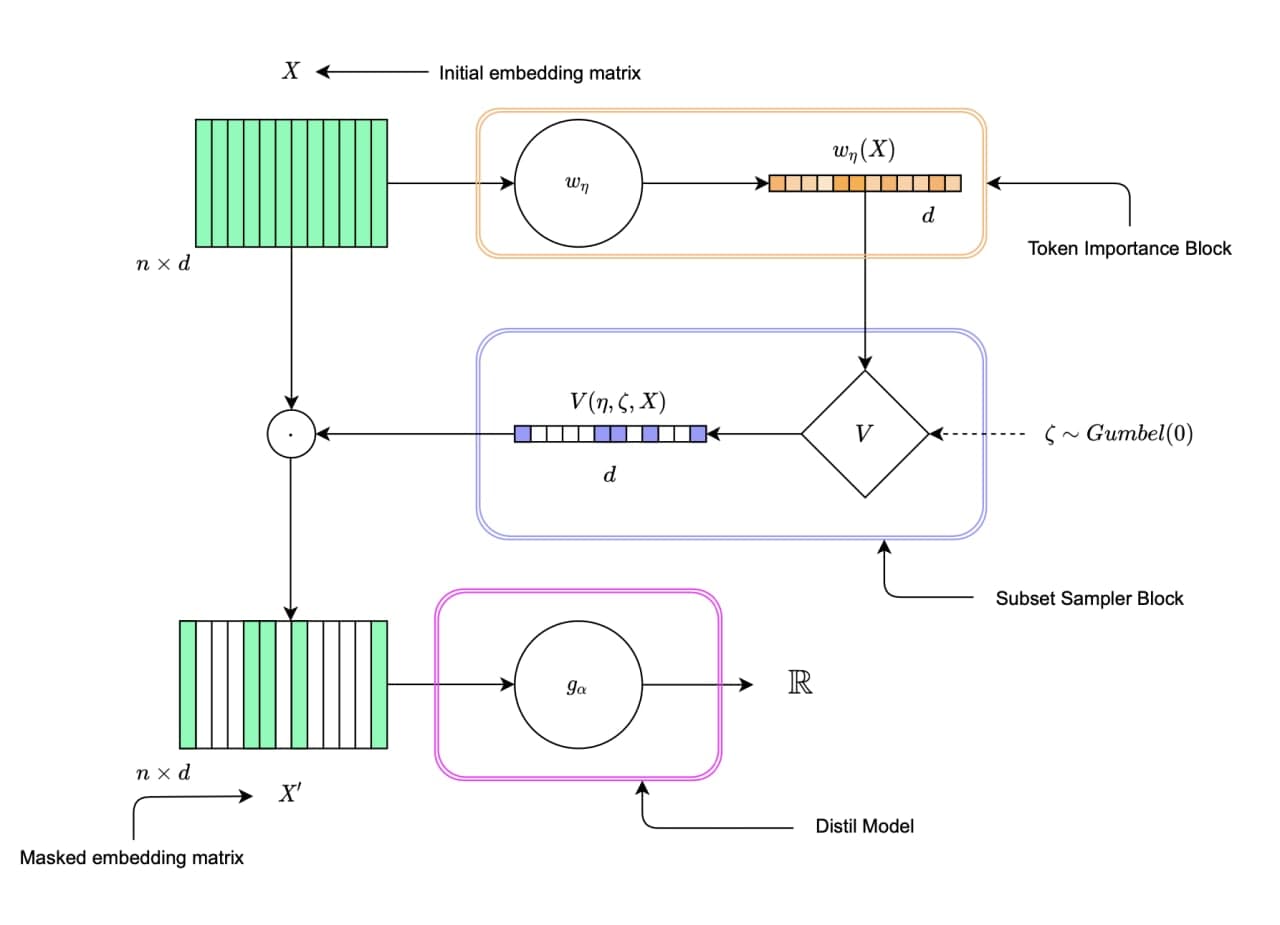
Some info about parameters:
n_important- number of important tokens;temperature- initial temperature used in gumbel softmax trick;train_device- device used for training;inference_device- device used for inference;verbose- verbose mode;binning_mode- for training we use batch sampling by the length of sequence. So, batch formed only by the sequences from the respect bin. This parameter used for method of automatic binning border choosing. There are two of them:'linear'(min-max binning, like linspace),'hist'(histogram binning).bins_number- number of bins in batch sampling process;n_epochs- number of epochs of training of the L2X;learning_rate- learning rate of L2X model;patience- number of epoches before learning rate decreasing (torch.optim.lr_scheduler.ReduceLROnPlateu);extreme_patience- number of epoches before early stopping by the validation dataset;train_batch_size- size of batch for training process;valid_batch_size- size of batch for validation process;temp_anneal_factor- annealing factor for temperature. The temperature will be multiplied by this coefficient every epoch.importance_sampler- specifies method of sampling importance (there are two of them'gumbeltopk'- method from the original paper,'softsub'- another method);max_vocab_length- maximum length of vocabular (vocabular build up frommax_vocab_lengththe most frequent tokens). Ifmax_vocab_lengthis-1then include all in train set.embedder- embedding dictionary or path to fasttext/dict of embeddings.
Some links for more info about L2X:
[30]:
l2x = L2XTextExplainer(automl, train_device='cuda:1',
inference_device='cuda:1',
embedding_dim=300,
gamma=0.1, temperature=2, temp_anneal_factor=0.95,
n_epochs=200, importance_sampler='gumbeltopk',
n_important=20, patience=25,
extreme_patience=30, trainable_embeds=True)
l2x.fit(train_data, valid_data, cols_to_explain='Review')
test: 100%|██████████| 2500/2500 [06:14<00:00, 6.67it/s]
test: 100%|██████████| 2500/2500 [06:15<00:00, 6.66it/s]
test: 100%|██████████| 313/313 [00:47<00:00, 6.66it/s]
test: 100%|██████████| 313/313 [00:46<00:00, 6.66it/s]
train nll (loss=7.8830): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.12it/s]
train nll (loss=1.4016): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.63it/s]
train nll (loss=1.3859): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.53it/s]
train nll (loss=1.3684): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.57it/s]
train nll (loss=1.0265): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.44it/s]
train nll (loss=0.7086): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.46it/s]
train nll (loss=0.6344): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.62it/s]
train nll (loss=0.5779): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.68it/s]
train nll (loss=0.5318): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.22it/s]
train nll (loss=0.4962): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.56it/s]
train nll (loss=0.4575): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.69it/s]
train nll (loss=0.4233): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.65it/s]
train nll (loss=0.3882): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.58it/s]
train nll (loss=0.3574): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.59it/s]
train nll (loss=0.3326): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.41it/s]
train nll (loss=0.3177): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.70it/s]
train nll (loss=0.2997): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.50it/s]
train nll (loss=0.2885): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.50it/s]
train nll (loss=0.2768): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.24it/s]
train nll (loss=0.2667): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.41it/s]
train nll (loss=0.2569): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.40it/s]
train nll (loss=0.2500): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.54it/s]
train nll (loss=0.2439): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.26it/s]
train nll (loss=0.2349): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.54it/s]
train nll (loss=0.2278): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.25it/s]
train nll (loss=0.2244): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.35it/s]
train nll (loss=0.2220): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.35it/s]
train nll (loss=0.2158): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.36it/s]
train nll (loss=0.2110): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.45it/s]
train nll (loss=0.2080): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.43it/s]
train nll (loss=0.2050): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.40it/s]
train nll (loss=0.2003): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.38it/s]
train nll (loss=0.1977): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.43it/s]
train nll (loss=0.1925): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.42it/s]
train nll (loss=0.1919): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.55it/s]
train nll (loss=0.1888): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.49it/s]
train nll (loss=0.1842): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.37it/s]
train nll (loss=0.1841): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.44it/s]
train nll (loss=0.1820): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.52it/s]
train nll (loss=0.1777): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.37it/s]
train nll (loss=0.1785): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.27it/s]
train nll (loss=0.1778): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.40it/s]
train nll (loss=0.1748): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.40it/s]
train nll (loss=0.1719): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.42it/s]
train nll (loss=0.1704): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.58it/s]
train nll (loss=0.1715): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.74it/s]
train nll (loss=0.1715): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.48it/s]
train nll (loss=0.1734): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.68it/s]
train nll (loss=0.1732): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.65it/s]
train nll (loss=0.1781): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.58it/s]
train nll (loss=0.1770): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.57it/s]
train nll (loss=0.1737): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.66it/s]
train nll (loss=0.1728): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.59it/s]
train nll (loss=0.1731): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.48it/s]
train nll (loss=0.1708): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.26it/s]
train nll (loss=0.1696): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.35it/s]
train nll (loss=0.1699): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.01it/s]
train nll (loss=0.1699): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.39it/s]
train nll (loss=0.1681): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.37it/s]
train nll (loss=0.1682): 100%|█████████▉| 1249/1251 [00:45<00:00, 27.39it/s]
train nll (loss=0.1684): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.57it/s]
train nll (loss=0.1666): 100%|█████████▉| 1249/1251 [00:46<00:00, 26.91it/s]
train nll (loss=0.1659): 100%|█████████▉| 1249/1251 [00:51<00:00, 24.20it/s]
train nll (loss=0.1656): 100%|█████████▉| 1249/1251 [00:46<00:00, 27.09it/s]
train nll (loss=0.1665): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.92it/s]
train nll (loss=0.1676): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.65it/s]
train nll (loss=0.1657): 100%|█████████▉| 1249/1251 [00:43<00:00, 29.02it/s]
train nll (loss=0.1651): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.92it/s]
train nll (loss=0.1631): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.87it/s]
train nll (loss=0.1634): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.79it/s]
train nll (loss=0.1634): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.77it/s]
train nll (loss=0.1626): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.40it/s]
train nll (loss=0.1631): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.35it/s]
train nll (loss=0.1613): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.44it/s]
train nll (loss=0.1614): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.63it/s]
train nll (loss=0.1638): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.51it/s]
train nll (loss=0.1633): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.52it/s]
train nll (loss=0.1618): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.39it/s]
train nll (loss=0.1612): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.43it/s]
train nll (loss=0.1628): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.34it/s]
train nll (loss=0.1616): 100%|█████████▉| 1249/1251 [00:41<00:00, 29.99it/s]
train nll (loss=0.1618): 100%|█████████▉| 1249/1251 [00:41<00:00, 29.77it/s]
train nll (loss=0.1594): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.29it/s]
train nll (loss=0.1617): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.55it/s]
train nll (loss=0.1617): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.27it/s]
train nll (loss=0.1610): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.35it/s]
train nll (loss=0.1590): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.35it/s]
train nll (loss=0.1602): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.49it/s]
train nll (loss=0.1602): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.07it/s]
train nll (loss=0.1613): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.80it/s]
train nll (loss=0.1620): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.86it/s]
train nll (loss=0.1593): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.95it/s]
train nll (loss=0.1612): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.89it/s]
train nll (loss=0.1620): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.93it/s]
train nll (loss=0.1614): 100%|█████████▉| 1249/1251 [00:44<00:00, 28.26it/s]
train nll (loss=0.1630): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.19it/s]
train nll (loss=0.1665): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.75it/s]
train nll (loss=0.1605): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.48it/s]
train nll (loss=0.1605): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.01it/s]
train nll (loss=0.1636): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.58it/s]
train nll (loss=0.1617): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.08it/s]
train nll (loss=0.1635): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.44it/s]
train nll (loss=0.1606): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.65it/s]
train nll (loss=0.1631): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.45it/s]
train nll (loss=0.1645): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.60it/s]
train nll (loss=0.1652): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.37it/s]
train nll (loss=0.1641): 100%|█████████▉| 1249/1251 [00:41<00:00, 29.96it/s]
train nll (loss=0.1669): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.80it/s]
train nll (loss=0.1610): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.11it/s]
train nll (loss=0.1630): 100%|█████████▉| 1249/1251 [00:43<00:00, 28.96it/s]
train nll (loss=0.1644): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.11it/s]
train nll (loss=0.1681): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.06it/s]
train nll (loss=0.1691): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.12it/s]
train nll (loss=0.1728): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.15it/s]
train nll (loss=0.1710): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.16it/s]
train nll (loss=0.1679): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.30it/s]
train nll (loss=0.1697): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.31it/s]
train nll (loss=0.1669): 100%|█████████▉| 1249/1251 [00:41<00:00, 29.92it/s]
train nll (loss=0.1708): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.28it/s]
train nll (loss=0.1662): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.56it/s]
train nll (loss=0.1739): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.34it/s]
train nll (loss=0.1977): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.68it/s]
train nll (loss=0.1844): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.72it/s]
train nll (loss=0.1685): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.17it/s]
train nll (loss=0.1664): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.48it/s]
train nll (loss=0.1760): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.63it/s]
train nll (loss=0.1678): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.71it/s]
train nll (loss=0.1681): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.25it/s]
train nll (loss=0.1806): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.67it/s]
train nll (loss=0.1724): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.70it/s]
train nll (loss=0.1691): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.67it/s]
train nll (loss=0.1712): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.71it/s]
train nll (loss=0.1762): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.55it/s]
train nll (loss=0.1655): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.00it/s]
train nll (loss=0.1860): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.72it/s]
train nll (loss=0.1897): 100%|█████████▉| 1249/1251 [00:41<00:00, 29.76it/s]
train nll (loss=0.1770): 100%|█████████▉| 1249/1251 [00:41<00:00, 30.45it/s]
train nll (loss=0.1796): 100%|█████████▉| 1249/1251 [00:42<00:00, 29.65it/s]
train nll (loss=0.1816): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.48it/s]
train nll (loss=0.1870): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.75it/s]
train nll (loss=0.1797): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.57it/s]
train nll (loss=0.1878): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.75it/s]
train nll (loss=0.1903): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.72it/s]
train nll (loss=0.1787): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.63it/s]
train nll (loss=0.1815): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.70it/s]
train nll (loss=0.1781): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.68it/s]
train nll (loss=0.1749): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.68it/s]
train nll (loss=0.1735): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.51it/s]
train nll (loss=0.1675): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.56it/s]
train nll (loss=0.1671): 100%|█████████▉| 1249/1251 [00:40<00:00, 30.58it/s]
[31]:
expl_train = l2x['Review'].explain_instances(train_data)
[32]:
expl_valid = l2x['Review'].explain_instances(valid_data)
Examples
[33]:
expl_valid[66].visualize_in_notebook()
Text
<START> lot exploder lost about 3 of this beer down the drain as foam whats left is a cloudy medium brown color with floaties plenty of head obviously which dissipates quickly aroma is tons of malt and dark fruit the flavor is again very fruity with bready malt and caramel notes a bit of roast malt no hint of spices anywhere full bodied with plenty of silky crispness <PAD>
[34]:
expl_valid[55].visualize_in_notebook()
Text
<START> whoa is right with this one this is a big brew in my opinion hence its name pours a thick creamy head and has a dark brown color with hints of amber the taste ha thick hops in here think of biting into a big juicy fruit terrapin comes out strong with this seasonal taste of alcohol is well hidden but will creap up on you in a hurry i have found this most of the year for some reason i guess they distributed alot of it in the atlanta area <PAD>
[35]:
expl_valid[77].visualize_in_notebook()
Text
<START> the beer pours an opaque light copper capped by a minimal off white head there s very little retention despite a robust pour into the glass the nose is simply divine i feel like i just pulled a freshly baked pumpkin pie out of the oven aromas of gram cracker and butterscotch covered shortbread mix with sweet potato and canned <UNK> pumpkin puree coconut cinnamon and a hint of citrus add a twist of the exotic liquid pumpkin pie is the best way to describe the flavour a fine pte sucre crust with a rich pumpkin filling spiced with cinnamon and allspice this really is devilishly good everything i found lacking in previous pumpkin beers this makes up for smooth creamy macadamia nuttiness adds another dimension hops are nearly <UNK> simple there for balance similarly absent is the taste of alcohol despite the whopping percentage only int he very finish does it pop up like a <UNK> child the medium body and medium low level of carbonation make for a surprisingly easy drinking beer dangerous this is the best pumpkin beer i ve ever had hands down <PAD>
[36]:
expl_valid[88].visualize_in_notebook()
Text
<START> og 5 p sg 046 1 abv pours out to a clear very pale golden forming a soapy white head with decent retention and good lacing carbonation is moderate aroma of weak floral hops with a touch of freesia corn and a light dryness mouthfeel is average watery with a light body and clean finish taste is predominated by corn with hardly any perceptable hop flavor or bitterness cleanly fermented with a crisp finish this is a very simple beer and only a step above budweiser if you need to transition someone from macro domestic swill to an average pale ale then this would be the one comparable to the lightest tap at any new brewpub easy to drink but then again why would i want to <PAD>
[37]:
expl_valid[121].visualize_in_notebook()
Text
<START> a blend of stout and bock cool hopefully better than a blend of wheat and <UNK> a inside joke for anyone who has worked as a grain handler not a good thing i know some beer gods frown on the whole black tan thing this is my first so in i dive in with my usual open <UNK> looked like watered down cola head fizzled fast not a good sign as it definitely was n t too cold hey decent lacing it s really trying to give me that chocolate coffee stout smell here but it s muted some slight coffe toffee taste initially with a hint of hop bitterness maybe even a little nutty but it seems to be out of balance hence the blending thing i guess very very thin and watery given it s parent ingredients got this in a beers of the world pack so bonus would certainly taste fairy exotic to a macro lager person but i wo n t be <UNK> my <UNK> account to get some more out of <UNK> usa anytime soon <PAD>
[38]:
expl_valid[888].visualize_in_notebook()
Text
<START> beer is a dark dark color with just the slightest hints of ruby at the edges and a coffee colored head beautiful to look at and almost as nice to drink the smell is coffee cocoa and just a hint of caramel or toffee with an underlying alcohol character and honey sweetness taste is very similar to the smell with the coffee and cocoa taking center stage and the alcohol almost overpowering the toffee and caramel notes luckily the sweetness helps to balance that out mouthfeel is good nice and thick with just a hint of stickiness the drinkability is n t the best i was actually surprised that this did n t have the highest abv of the beers i had at dragonmead that being said it was a perfectly enjoyable beer and i d jump at the chance to have another <PAD>
[39]:
expl_valid[999].visualize_in_notebook()
Text
<START> ten fidy another thanks to <UNK> for the trade bod 17 pours a rusted mahoghany and settles jet metal black a fingers worth of burnt caramel head sits for a short while the edges leave very little light to pass through spotty lacing clings throughout the nose brings a lot of milk chocolate that has a bittering end to it roasted malts and a presence of alcohol are also noted the taste is interesting the roasty malts bloom but an annoying metallic taste lingers there is a light hop presence as it warms the flavors intensify the mouthfeel is very full bodied and sits like an <UNK> creamy feel with good carbonation overall pretty good impy stout but that metal taste was a bit off putting i would like to try this fresh to see if there is a difference <PAD>
[40]:
expl_valid[333].visualize_in_notebook()
Text
<START> this is a wow witbier cloudy yellow with tendencies toward something darker more orange the head is a little flat though there s a good flowery perfume aroma soft citrus light coriander come up front wiht a good dry wheat in the finish this is a little heftier than the supposed style stalwart hoegaarden but the soft almost creamy mouthfeel makes this a surprisingly satisfying beer without being heavy tasty beer <PAD>
[41]:
expl_valid[111].visualize_in_notebook()
Text
<START> dark black with creamy tan head that leaves great retention and foamy lace the smell is roasty with burnt sugar edges dark chocolate coffee and smoke the taste is ashy too much black patent perhaps others enjoy this but there is a charcoal burnt taste that is a bit much for me smoky bitter chocolate and roasted coffee quite roasty and ashy tasting strong with alcohol peeking through overall an average stout <PAD>
[42]:
expl_valid[100].visualize_in_notebook()
Text
<START> reviewing the oaked arrogant bastard ale from stone brewing company a hearty thank you to beeradvocate user funhog for hooking me up with this one score appearance pours a dark red brown color with plenty of opaque ish ruby highlights with three fingers of cream colored head excellent lacing and the head really stick around if not apparent by the photo proprietary 5 smell piney citrusy hops and oak wood up front creamy chocolate a little caramel and figs oranges tangerines and malts 5 taste very sweet caramel and citrus hoppy with toasted maltiness slightly bitter finish 5 mouthfeel medium bodied oily and cream low carbonation complements the viscosity well dry bitter finish 5 overall a very solid brew but the original version arrogant bastard ale is better in my opinion double bastard is even better this beer is absolutely worth trying but a six pack seems a bit much on quantity for me i guess i have some extras for future ba trades recommendation i can certainly recommend this one to both beer geeks and casual beer drinkers as the flavors are pretty solid and not overwhelming but the oaking does not seem to add enough additional character flavor to justify the steep price jump i would most recommend this beer as one to add to a mix a six pairings hamburger cost 99 for a six pack <PAD>
[43]:
expl_valid[1021].visualize_in_notebook()
Text
<START> 750ml bottle into a tulip huge thanks to kevin for sharing this ancient oddity a muddy magenta brown body with a handful of off white bubbles meh s old musty oaky dirty vaguely reminiscent of tequila in a very weird way i do n t know that i ve ever smelled a more basementy beer and i kind of like it in a masochistic way t like liquid dementia so so old and yet still tasty some moderate sourness and acidic fruitiness is still there to provide at least a hint at what this beer used to be i dig it m smooth soft amazingly delicate o this was n t exactly delicious but it was a great experience i wish i d gotten the chance to taste this five years ago cheers <PAD>
[44]:
expl_valid[9999].visualize_in_notebook()
Text
<START> the apperance was an amber dark yellow color with not much head it did however have stuff floating in it i m not certain if that was of the fault of the manufacturer or the fault of myself for trusting my friends around my <UNK> drink any who the smell was bellow average although not always clearly present the taste was a sweet sour mix with a main taste of bitterness mouthfeel was smooth esque drinkability was average but seeing as i m a big time <UNK> and seeing as it s what my friends have i will most likely be having another very soon <PAD>
[45]:
expl_valid[7676].visualize_in_notebook()
Text
<START> pale gold with a thin film around the edge some lacing looks very flat and insipid no carbonation i do n t hold out much hope very unpleasant sticky rice nose lots of nothingness as well sweet with a very light sickly note but do n t get me wrong it s incredibly bland blech thin but fortunately not overly sweet on the palate quite clean and dry with a light lingering bitterness mouthfeel is quite crisp which is a blessing no it s not great but i was expecting a lot lot worse it s really not that bad when you get down to it it s not amazing but it s pretty clean and light i guess i m just pleased it does n t have the sweet sickly character promised on the nose <PAD>
[46]:
expl_valid[6767].visualize_in_notebook()
Text
<START> i was actually a little surprised by this one surprised it was not vile pours a clear gold color with a thin white head no real lacing to speak of and the head was short lived the aroma is lightly sweet which was another surprise light bodied with a barely average hops flavor the finish is a little sweet and a little fruity this is n t a beer i would seek out again but i would drink it in korea over a bud <PAD>
[47]:
expl_valid[3131].visualize_in_notebook()
Text
<START> pours a clear deep red brown with a big white head malty sweet no major flavors stand out though it is slightly toasty hops are clean and mellow they only come in near the end and help to balance the beer this is a solid simple brown it s so great to finally see organic beer in the store <PAD>