Tutorial 2: AutoWoE (WhiteBox model for binary classification on tabular data)
![]()
Official LightAutoML github repository is here
Scorecard
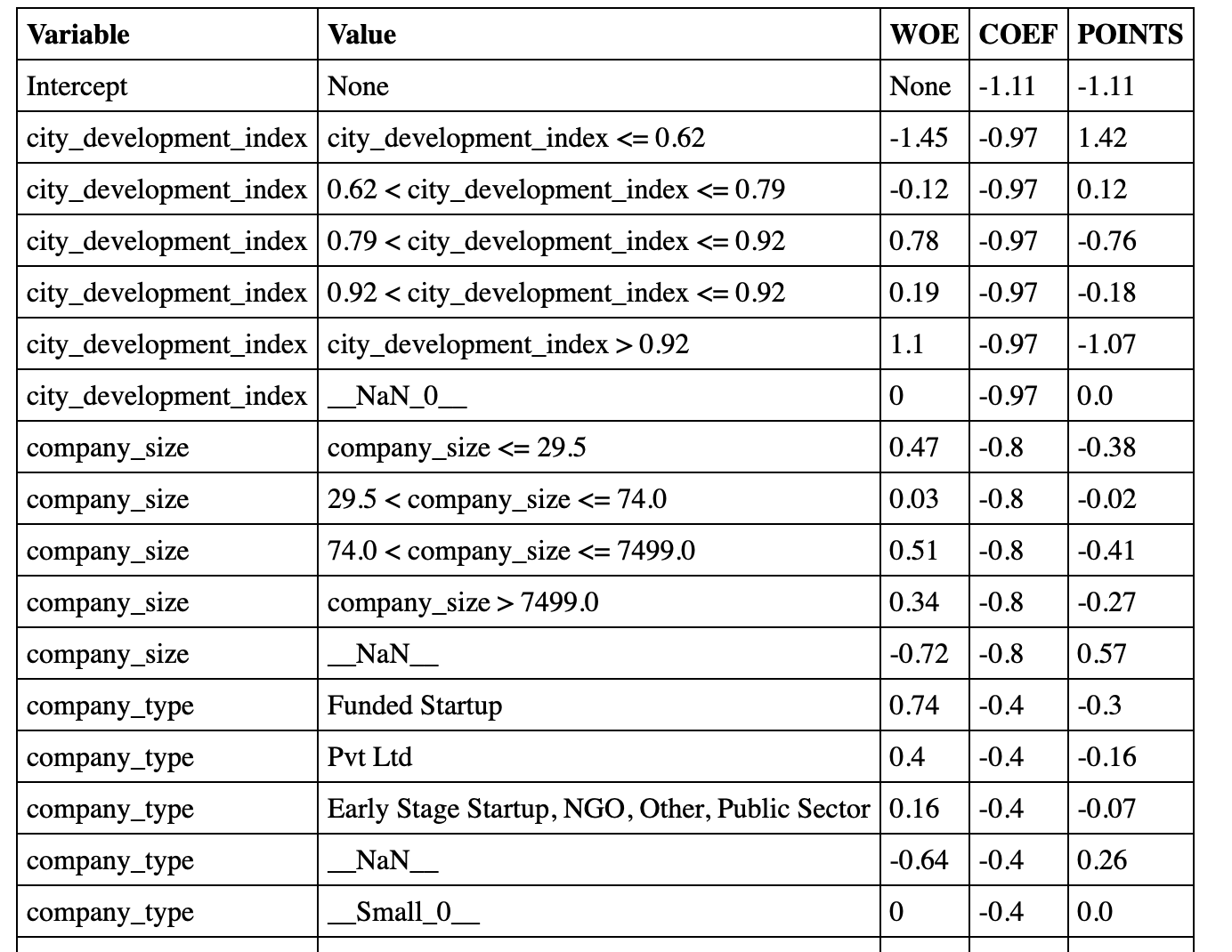
Linear model
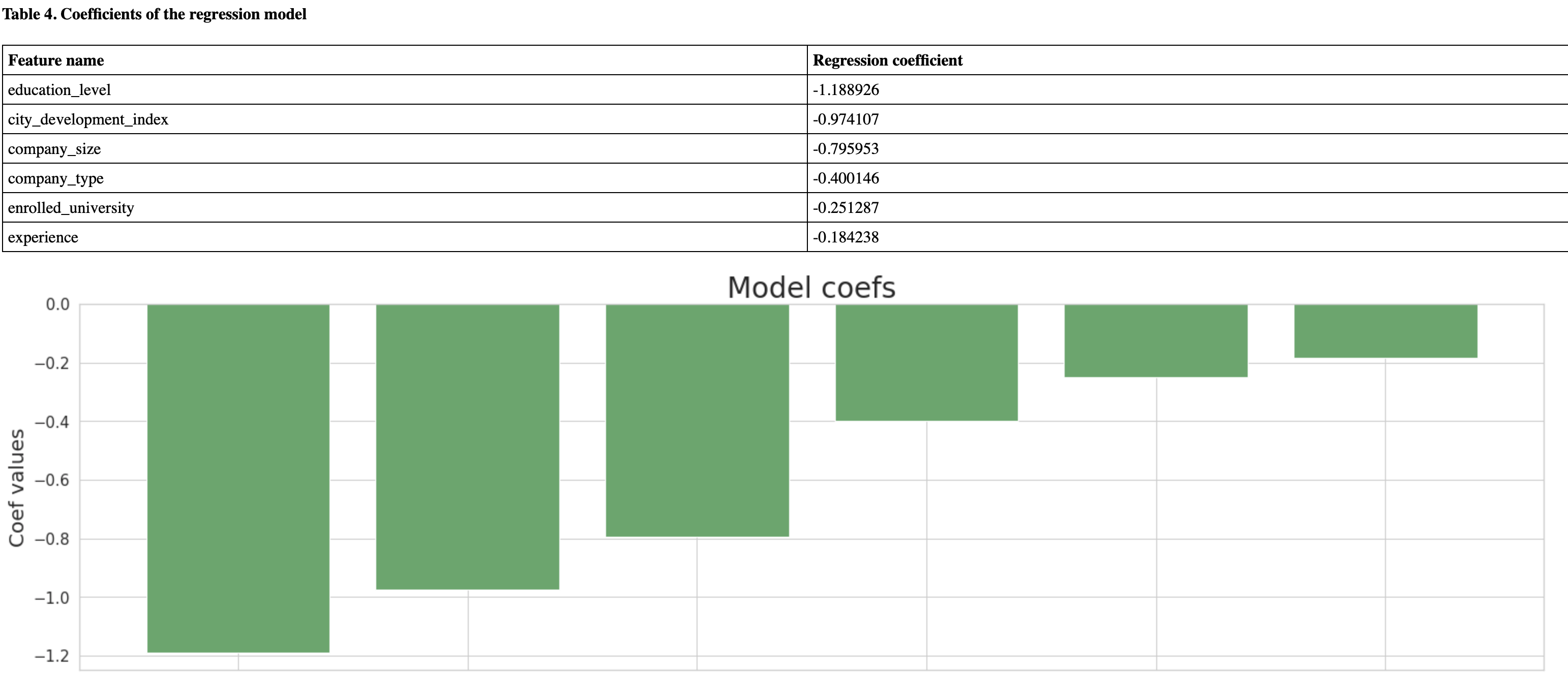
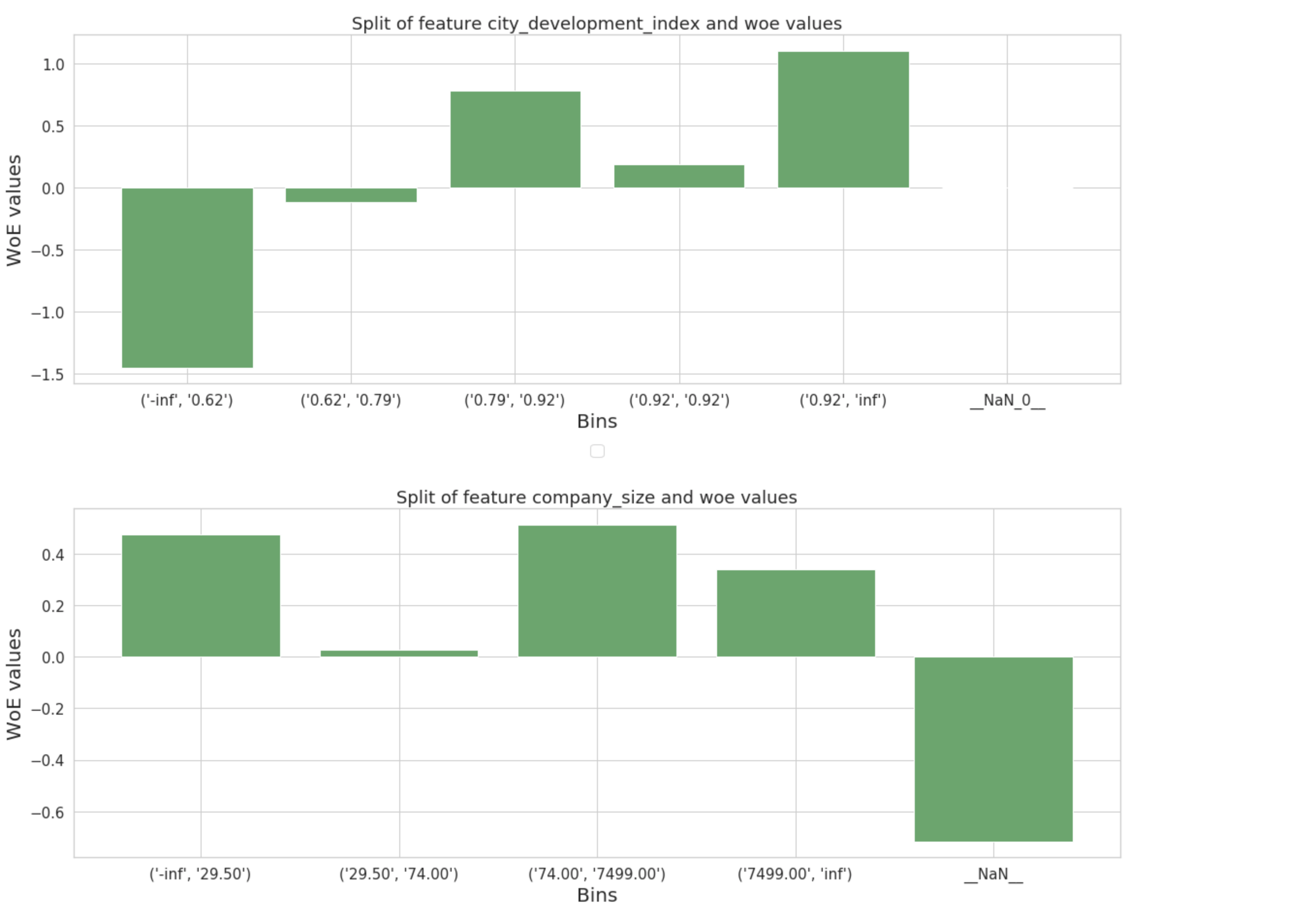
Discretization
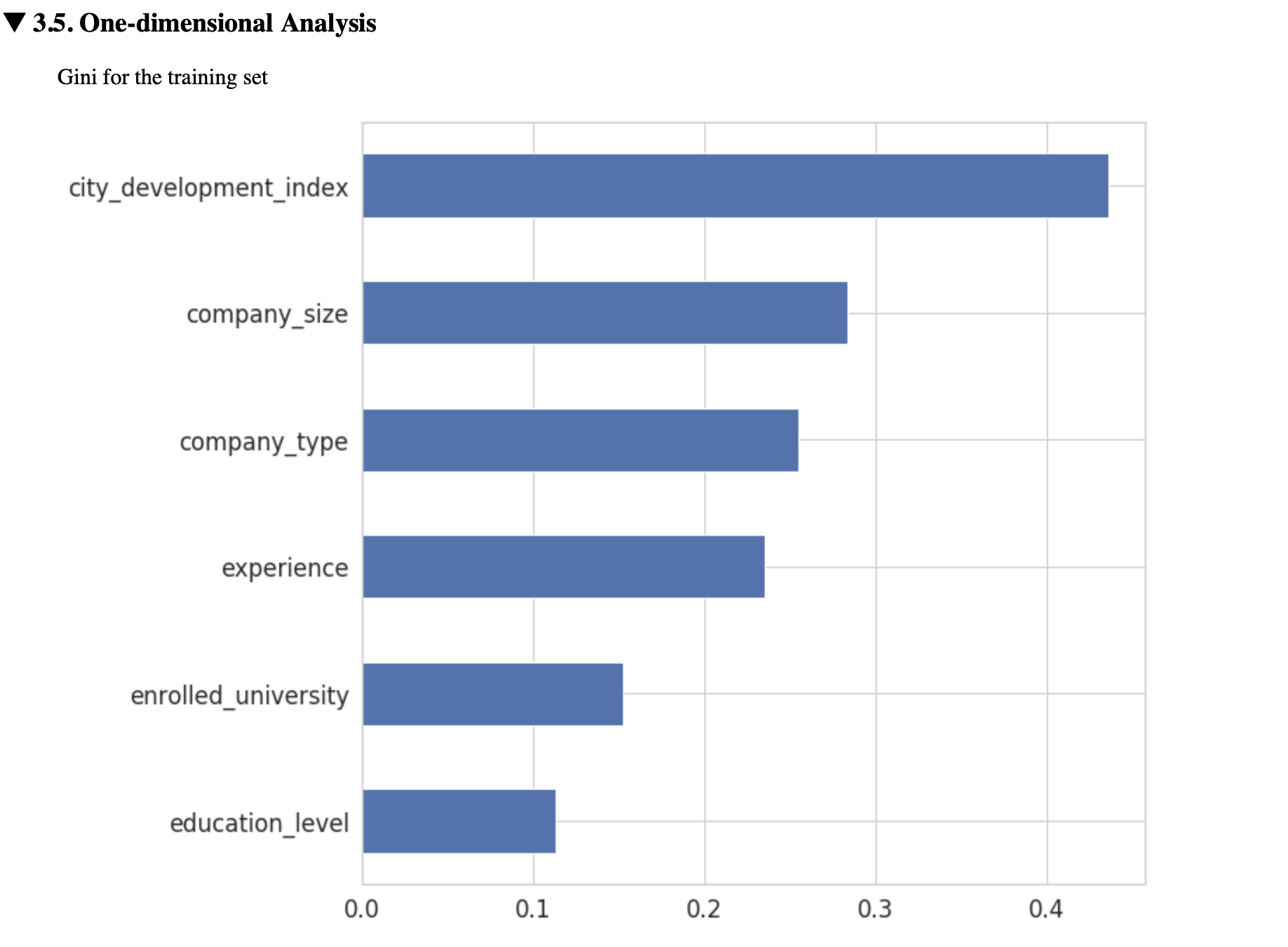
Selection and One-dimensional analysis
Whitebox pipeline:
General parameters
Technical
n_jobs
debug
Simple features typing and initial cleaning
1.1. Remove trash features
Medium: - th_nan - th_const1.2. Typling (auto or user defined)
Critical: - features_type (dict) {'age': 'real', 'education': 'cat', 'birth_date': (None, ("d", "wd"), ...}1.3. Categories and datetimes encoding
Critical: - features_type (for datetimes) Optional: - cat_alpha (int) - greater means more conservative encodingPre selection (based on BlackBox model importances)
Critical:
select_type (None or int)
imp_type (if type(select_type) is int ‘perm_imt’/’feature_imp’)
Optional:
imt_th (float) - threshold for select_type is None
Binning (discretization)
Critical:
monotonic / features_monotone_constraints
max_bin_count / max_bin_count
min_bin_size
cat_merge_to
nan_merge_to
Medium:
force_single_split
Optional:
min_bin_mults
min_gains_to_split
WoE estimation WoE = LN( ((% 0 in bin) / (% 0 in sample)) / ((% 1 in bin) / (% 1 in sample)) ):
Critical:
oof_woe
Optional:
woe_diff_th
n_folds (if oof_woe)
2nd selection stage:
5.1. One-dimentional importance
Critical: - auc_th5.2. VIF
Critical: - vif_th5.3. Partial correlations
Critical: - pearson_th3rd selection stage (model based)
Optional:
n_folds
l1_base_step
l1_exp_step
Do not touch:
population_size
feature_groups_count
Fitting the final model
Critical:
regularized_refit
p_val (if not regularized_refit)
validation (if not regularized_refit)
Optional:
interpreted_model
l1_base_step (if regularized_refit)
l1_exp_step (if regularized_refit)
Report generation
report_params
Imports
[25]:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import os
import requests
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from autowoe import AutoWoE, ReportDeco
Reading the data and train/test split
[26]:
DATASET_DIR = '../data/'
DATASET_NAME = 'jobs_train.csv'
DATASET_FULLNAME = os.path.join(DATASET_DIR, DATASET_NAME)
DATASET_URL = 'https://raw.githubusercontent.com/AILab-MLTools/LightAutoML/master/examples/data/jobs_train.csv'
[27]:
%%time
if not os.path.exists(DATASET_FULLNAME):
os.makedirs(DATASET_DIR, exist_ok=True)
dataset = requests.get(DATASET_URL).text
with open(DATASET_FULLNAME, 'w') as output:
output.write(dataset)
CPU times: user 322 μs, sys: 0 ns, total: 322 μs
Wall time: 210 μs
[28]:
data = pd.read_csv(DATASET_FULLNAME)
[29]:
data
[29]:
| enrollee_id | city | city_development_index | gender | relevant_experience | enrolled_university | education_level | major_discipline | experience | company_size | company_type | last_new_job | training_hours | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8949 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 21.0 | NaN | NaN | 1.0 | 36 | 1.0 |
| 1 | 29725 | city_40 | 0.776 | Male | No relevant experience | no_enrollment | Graduate | STEM | 15.0 | 99.0 | Pvt Ltd | 5.0 | 47 | 0.0 |
| 2 | 11561 | city_21 | 0.624 | NaN | No relevant experience | Full time course | Graduate | STEM | 5.0 | NaN | NaN | 0.0 | 83 | 0.0 |
| 3 | 33241 | city_115 | 0.789 | NaN | No relevant experience | NaN | Graduate | Business Degree | 0.0 | NaN | Pvt Ltd | 0.0 | 52 | 1.0 |
| 4 | 666 | city_162 | 0.767 | Male | Has relevant experience | no_enrollment | Masters | STEM | 21.0 | 99.0 | Funded Startup | 4.0 | 8 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19153 | 7386 | city_173 | 0.878 | Male | No relevant experience | no_enrollment | Graduate | Humanities | 14.0 | NaN | NaN | 1.0 | 42 | 1.0 |
| 19154 | 31398 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 14.0 | NaN | NaN | 4.0 | 52 | 1.0 |
| 19155 | 24576 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 21.0 | 99.0 | Pvt Ltd | 4.0 | 44 | 0.0 |
| 19156 | 5756 | city_65 | 0.802 | Male | Has relevant experience | no_enrollment | High School | NaN | 0.0 | 999.0 | Pvt Ltd | 2.0 | 97 | 0.0 |
| 19157 | 23834 | city_67 | 0.855 | NaN | No relevant experience | no_enrollment | Primary School | NaN | 2.0 | NaN | NaN | 1.0 | 127 | 0.0 |
19158 rows × 14 columns
[30]:
train, test = train_test_split(data.drop('enrollee_id', axis=1), test_size=0.2, stratify=data['target'])
AutoWoe: default settings
[31]:
auto_woe_0 = AutoWoE(interpreted_model=True,
monotonic=False,
max_bin_count=5,
select_type=None,
pearson_th=0.9,
metric_th=.505,
vif_th=10.,
imp_th=0,
th_const=32,
force_single_split=True,
th_nan=0.01,
th_cat=0.005,
metric_tol=1e-4,
cat_alpha=100,
cat_merge_to="to_woe_0",
nan_merge_to="to_woe_0",
imp_type="feature_imp",
regularized_refit=False,
p_val=0.05,
verbose=2
)
auto_woe_0 = ReportDeco(auto_woe_0, )
[32]:
auto_woe_0.fit(train,
target_name="target",
)
[LightGBM] [Info] Number of positive: 3027, number of negative: 9233
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000615 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 512
[LightGBM] [Info] Number of data points in the train set: 12260, number of used features: 12
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.246900 -> initscore=-1.115212
[LightGBM] [Info] Start training from score -1.115212
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[10] val_test's auc: 0.798546
city processing...
city_development_index processing...
gender processing...
relevant_experience processing...
enrolled_university processing...
education_level processing...
experience processing...
company_size processing...
company_type processing...
last_new_job processing...
training_hours processing...
dict_keys(['city', 'city_development_index', 'gender', 'relevant_experience', 'enrolled_university', 'education_level', 'experience', 'company_size', 'company_type', 'last_new_job', 'training_hours']) to selector !!!!!
Feature selection...
city_development_index -0.986582
company_size -0.816660
company_type -0.400413
experience -0.189662
enrolled_university -0.209603
education_level -1.169475
dtype: float64
[33]:
test_prediction = auto_woe_0.predict_proba(test)
test_prediction
[33]:
array([0.07859696, 0.26590075, 0.0693864 , ..., 0.12662937, 0.14364888,
0.47728299])
[34]:
roc_auc_score(test['target'].values, test_prediction)
[34]:
0.7882607500905356
[35]:
report_params = {"output_path": "HR_REPORT_1", # folder for report generation
"report_name": "WHITEBOX REPORT",
"report_version_id": 1,
"city": "Moscow",
"model_aim": "Predict if candidate will work for the company",
"model_name": "HR model",
"zakazchik": "Kaggle",
"high_level_department": "Ai Lab",
"ds_name": "Btbpanda",
"target_descr": "Candidate will work for the company",
"non_target_descr": "Candidate will work for the company"}
auto_woe_0.generate_report(report_params, )
AutoWoE - simpler model
[36]:
auto_woe_1 = AutoWoE(interpreted_model=True,
monotonic=True,
max_bin_count=4,
select_type=None,
pearson_th=0.9,
metric_th=.505,
vif_th=10.,
imp_th=0,
th_const=32,
force_single_split=True,
th_nan=0.01,
th_cat=0.005,
metric_tol=1e-4,
cat_alpha=100,
cat_merge_to="to_woe_0",
nan_merge_to="to_woe_0",
imp_type="feature_imp",
regularized_refit=False,
p_val=0.05,
verbose=2
)
auto_woe_1 = ReportDeco(auto_woe_1, )
[37]:
auto_woe_1.fit(train,
target_name="target",
)
[LightGBM] [Info] Number of positive: 3027, number of negative: 9233
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000498 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 512
[LightGBM] [Info] Number of data points in the train set: 12260, number of used features: 12
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.246900 -> initscore=-1.115212
[LightGBM] [Info] Start training from score -1.115212
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[10] val_test's auc: 0.798546
city processing...
city_development_index processing...
gender processing...
relevant_experience processing...
enrolled_university processing...
education_level processing...
experience processing...
company_size processing...
company_type processing...
last_new_job processing...
training_hours processing...
dict_keys(['city', 'city_development_index', 'gender', 'relevant_experience', 'enrolled_university', 'education_level', 'experience', 'company_size', 'company_type', 'last_new_job', 'training_hours']) to selector !!!!!
Feature selection...
city -0.537704
city_development_index -0.501377
company_size -0.820035
company_type -0.424950
experience -0.193515
enrolled_university -0.162144
education_level -1.230515
dtype: float64
[38]:
test_prediction = auto_woe_1.predict_proba(test)
test_prediction
[38]:
array([0.08448153, 0.23365578, 0.06406811, ..., 0.10791522, 0.13339279,
0.45904027])
[39]:
roc_auc_score(test['target'].values, test_prediction)
[39]:
0.7859235642130127
[40]:
report_params = {"output_path": "HR_REPORT_2", # folder for report generation
"report_name": "WHITEBOX REPORT",
"report_version_id": 2,
"city": "Moscow",
"model_aim": "Predict if candidate will work for the company",
"model_name": "HR model",
"zakazchik": "Kaggle",
"high_level_department": "Ai Lab",
"ds_name": "Btbpanda",
"target_descr": "Candidate will work for the company",
"non_target_descr": "Candidate will work for the company"}
auto_woe_1.generate_report(report_params, )
WhiteBox preset - like TabularAutoML
[41]:
from lightautoml.automl.presets.whitebox_presets import WhiteBoxPreset
from lightautoml.task import Task
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[41], line 2
1 from lightautoml.automl.presets.whitebox_presets import WhiteBoxPreset
----> 2 from lightautoml.task import Task
ModuleNotFoundError: No module named 'lightautoml.task'
[ ]:
task = Task('binary')
automl = WhiteBoxPreset(task)
[ ]:
train_pred = automl.fit_predict(train.reset_index(drop=True), roles={'target': 'target'})
Validation data is not set. Train will be used as valid in report and valid prediction
Start automl preset with listed constraints:
- time: 3600 seconds
- cpus: 4 cores
- memory: 16 gb
Train data shape: (15326, 13)
Feats was rejected during automatic roles guess: []
Layer 1 ...
Train process start. Time left 3595.0072581768036 secs
Start fitting Lvl_0_Pipe_0_Mod_0_WhiteBox ...
===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_WhiteBox =====
features [] contain too many nans or identical values
features [] have low importance
city processing...
city_development_index processing...company_type processing...education_level processing...
enrolled_university processing...
gender processing...
major_discipline processing...
relevent_experience processing...
company_size processing...
experience processing...
last_new_job processing...
training_hours processing...
dict_keys(['city', 'city_development_index', 'company_type', 'education_level', 'enrolled_university', 'gender', 'major_discipline', 'relevent_experience', 'company_size', 'experience', 'last_new_job', 'training_hours']) to selector !!!!!
Feature selection...
Feature training_hours removed due to low AUC value 0.5031265374717342
Feature city_development_index removed due to high VIF value = 40.56438648184099
C parameter range in [0.0002603488674824265:260.3488674824265], 20 values
Result(score=0.7856775296767177, reg_alpha=0.020431136952654548, is_neg=True, min_weights=city -0.980620
company_size -0.800535
company_type -0.340185
experience -0.198176
enrolled_university -0.101047
relevent_experience 0.000000
education_level -0.624324
last_new_job 0.000000
gender 0.000000
major_discipline -0.317699
dtype: float64)
Iter 0 of final refit starts with 7 features
Validation data checks
city -0.956550
company_size -0.866063
company_type -0.402941
experience -0.329493
enrolled_university -0.230776
education_level -0.641994
major_discipline -1.596907
dtype: float64
Lvl_0_Pipe_0_Mod_0_WhiteBox fitting and predicting completed
Time left 3587.2280378341675
Automl preset training completed in 12.77 seconds.
[ ]:
test_prediction = automl.predict(test).data[:, 0]
[ ]:
roc_auc_score(test['target'].values, test_prediction)
0.7966826628232216
Serialization
Important note: auto_woe_1 is the ReportDeco object (the report generator object), not AutoWoE itself. To receive the AutoWoE object you can use the auto_woe_1.model.
ReportDeco object usage for inference is not recommended for several reasons: - The report object needs to have the target column because of model quality metrics calculation - Model inference using ReportDeco object is slower than the usual one because of the report update procedure
[ ]:
joblib.dump(auto_woe_1.model, 'model.pkl')
model = joblib.load('model.pkl')
SQL inference query
[21]:
sql_query = model.get_sql_inference_query('global_temp.TABLE_1')
print(sql_query)
SELECT
1 / (1 + EXP(-(
-1.111
-0.516*WOE_TAB.city
-0.513*WOE_TAB.city_development_index
-0.815*WOE_TAB.company_size
-0.398*WOE_TAB.company_type
-0.175*WOE_TAB.experience
-0.22*WOE_TAB.enrolled_university
-1.24*WOE_TAB.education_level
))) as PROB,
WOE_TAB.*
FROM
(SELECT
CASE
WHEN (city IS NULL OR LOWER(CAST(city AS VARCHAR(50))) = 'nan') THEN 0
WHEN city IN ('city_100', 'city_102', 'city_103', 'city_116', 'city_149', 'city_159', 'city_160', 'city_45', 'city_46', 'city_64', 'city_71', 'city_73', 'city_83', 'city_99') THEN 0.213
WHEN city IN ('city_104', 'city_114', 'city_136', 'city_138', 'city_16', 'city_173', 'city_23', 'city_28', 'city_36', 'city_50', 'city_57', 'city_61', 'city_65', 'city_67', 'city_75', 'city_97') THEN 1.017
WHEN city IN ('city_11', 'city_21', 'city_74') THEN -1.455
ELSE -0.209
END AS city,
CASE
WHEN (city_development_index IS NULL OR city_development_index = 'NaN') THEN 0
WHEN city_development_index <= 0.6245 THEN -1.454
WHEN city_development_index <= 0.7915 THEN -0.121
WHEN city_development_index <= 0.9235 THEN 0.461
ELSE 1.101
END AS city_development_index,
CASE
WHEN (company_size IS NULL OR company_size = 'NaN') THEN -0.717
WHEN company_size <= 74.0 THEN 0.221
ELSE 0.467
END AS company_size,
CASE
WHEN (company_type IS NULL OR LOWER(CAST(company_type AS VARCHAR(50))) = 'nan') THEN -0.64
WHEN company_type IN ('Early Stage Startup', 'NGO', 'Other', 'Public Sector') THEN 0.164
WHEN company_type = 'Funded Startup' THEN 0.737
WHEN company_type = 'Pvt Ltd' THEN 0.398
ELSE 0
END AS company_type,
CASE
WHEN (experience IS NULL OR experience = 'NaN') THEN 0
WHEN experience <= 1.5 THEN -0.811
WHEN experience <= 7.5 THEN -0.319
WHEN experience <= 11.5 THEN 0.119
ELSE 0.533
END AS experience,
CASE
WHEN (enrolled_university IS NULL OR LOWER(CAST(enrolled_university AS VARCHAR(50))) = 'nan') THEN -0.327
WHEN enrolled_university = 'Full time course' THEN -0.614
WHEN enrolled_university = 'Part time course' THEN 0.026
WHEN enrolled_university = 'no_enrollment' THEN 0.208
ELSE 0
END AS enrolled_university,
CASE
WHEN (education_level IS NULL OR LOWER(CAST(education_level AS VARCHAR(50))) = 'nan') THEN 0.21
WHEN education_level = 'Graduate' THEN -0.166
WHEN education_level = 'High School' THEN 0.34
WHEN education_level = 'Masters' THEN 0.21
WHEN education_level IN ('Phd', 'Primary School') THEN 0.704
ELSE 0
END AS education_level
FROM global_temp.TABLE_1) as WOE_TAB
Check the SQL query by PySpark
[23]:
from pyspark.sql import SparkSession
[ ]:
spark = SparkSession.builder \
.master("local[2]") \
.appName("spark-course") \
.config("spark.driver.memory", "512m") \
.getOrCreate()
sc = spark.sparkContext
[24]:
spark_df = spark.read.csv("jobs_train.csv", header=True)
spark_df.createGlobalTempView("TABLE_1")
[25]:
res = spark.sql(sql_query).toPandas()
[26]:
res
[26]:
| PROB | city | city_development_index | company_size | company_type | experience | enrolled_university | education_level | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.365512 | 0.213 | 0.461 | -0.717 | -0.640 | 0.533 | 0.208 | -0.166 |
| 1 | 0.195716 | -0.209 | -0.121 | 0.467 | 0.398 | 0.533 | 0.208 | -0.166 |
| 2 | 0.835002 | -1.455 | -1.454 | -0.717 | -0.640 | -0.319 | -0.614 | -0.166 |
| 3 | 0.476161 | -0.209 | -0.121 | -0.717 | 0.398 | -0.811 | -0.327 | -0.166 |
| 4 | 0.117694 | -0.209 | -0.121 | 0.467 | 0.737 | 0.533 | 0.208 | 0.210 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19153 | 0.275602 | 1.017 | 0.461 | -0.717 | -0.640 | 0.533 | 0.208 | -0.166 |
| 19154 | 0.365512 | 0.213 | 0.461 | -0.717 | -0.640 | 0.533 | 0.208 | -0.166 |
| 19155 | 0.126794 | 0.213 | 0.461 | 0.467 | 0.398 | 0.533 | 0.208 | -0.166 |
| 19156 | 0.060842 | 1.017 | 0.461 | 0.467 | 0.398 | -0.811 | 0.208 | 0.340 |
| 19157 | 0.130552 | 1.017 | 0.461 | -0.717 | -0.640 | -0.319 | 0.208 | 0.704 |
19158 rows × 8 columns
[27]:
sc.stop()
[28]:
full_prediction = model.predict_proba(data)
full_prediction
[28]:
array([0.36557352, 0.19577798, 0.83497665, ..., 0.12678668, 0.06083813,
0.13061427])
[29]:
(res['PROB'] - full_prediction).abs().max()
[29]:
0.0002878641803194526