Tutorial 9: Neural Networks
![]()
Official LightAutoML github repository is here
In this tutorial you will learn how to:
train neural networks (nn) with LightAutoML on tabualr data
customize model architecture and pipelines
0. Prerequisites
0.0 install LightAutoML
[1]:
# !pip install -U lightautoml[all]
0.1 Import libraries
Here we will import the libraries we use in this kernel:
Standard python libraries for timing, working with OS etc.
Essential python DS libraries like numpy, pandas, scikit-learn and torch (the last we will use in the next cell)
LightAutoML modules: presets for AutoML, task and report generation module
[2]:
# Standard python libraries
import os
# Essential DS libraries
import optuna
import requests
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import torch
from copy import deepcopy as copy
import torch.nn as nn
from collections import OrderedDict
# LightAutoML presets, task and report generation
from lightautoml.automl.presets.tabular_presets import TabularAutoML
from lightautoml.tasks import Task
0.2 Constants
Here we setup the constants to use in the kernel:
N_THREADS- number of vCPUs for LightAutoML model creationN_FOLDS- number of folds in LightAutoML inner CVRANDOM_STATE- random seed for better reproducibilityTEST_SIZE- houldout data part sizeTIMEOUT- limit in seconds for model to trainTARGET_NAME- target column name in dataset
[3]:
N_THREADS = 4
N_FOLDS = 5
RANDOM_STATE = 42
TEST_SIZE = 0.2
TIMEOUT = 300
TARGET_NAME = 'TARGET'
np.random.seed(RANDOM_STATE)
torch.set_num_threads(N_THREADS)
0.3 Data loading
[4]:
DATASET_DIR = '../data/'
DATASET_NAME = 'sampled_app_train.csv'
DATASET_FULLNAME = os.path.join(DATASET_DIR, DATASET_NAME)
DATASET_URL = 'https://raw.githubusercontent.com/AILab-MLTools/LightAutoML/master/examples/data/sampled_app_train.csv'
if not os.path.exists(DATASET_FULLNAME):
os.makedirs(DATASET_DIR, exist_ok=True)
dataset = requests.get(DATASET_URL).text
with open(DATASET_FULLNAME, 'w') as output:
output.write(dataset)
data = pd.read_csv(DATASET_FULLNAME)
data.head()
tr_data, te_data = train_test_split(
data,
test_size=TEST_SIZE,
stratify=data[TARGET_NAME],
random_state=RANDOM_STATE
)
1. Available built-in models
To use different model pass it to the list in "use_algo". We support custom models inherited from torch.nn.Module class. For every model their parameters is listed below.
1.1 MLP ("mlp")
hidden_size- define hidden layer dimensions
1.2 Dense Light ("denselight")
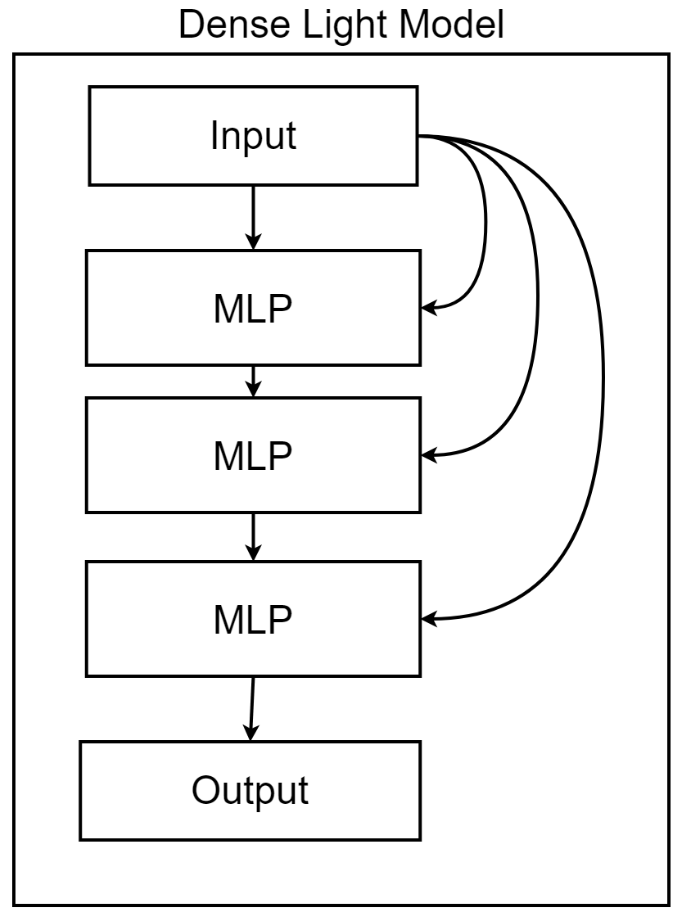
hidden_size- define hidden layer dimensions
1.3 Dense ("dense")
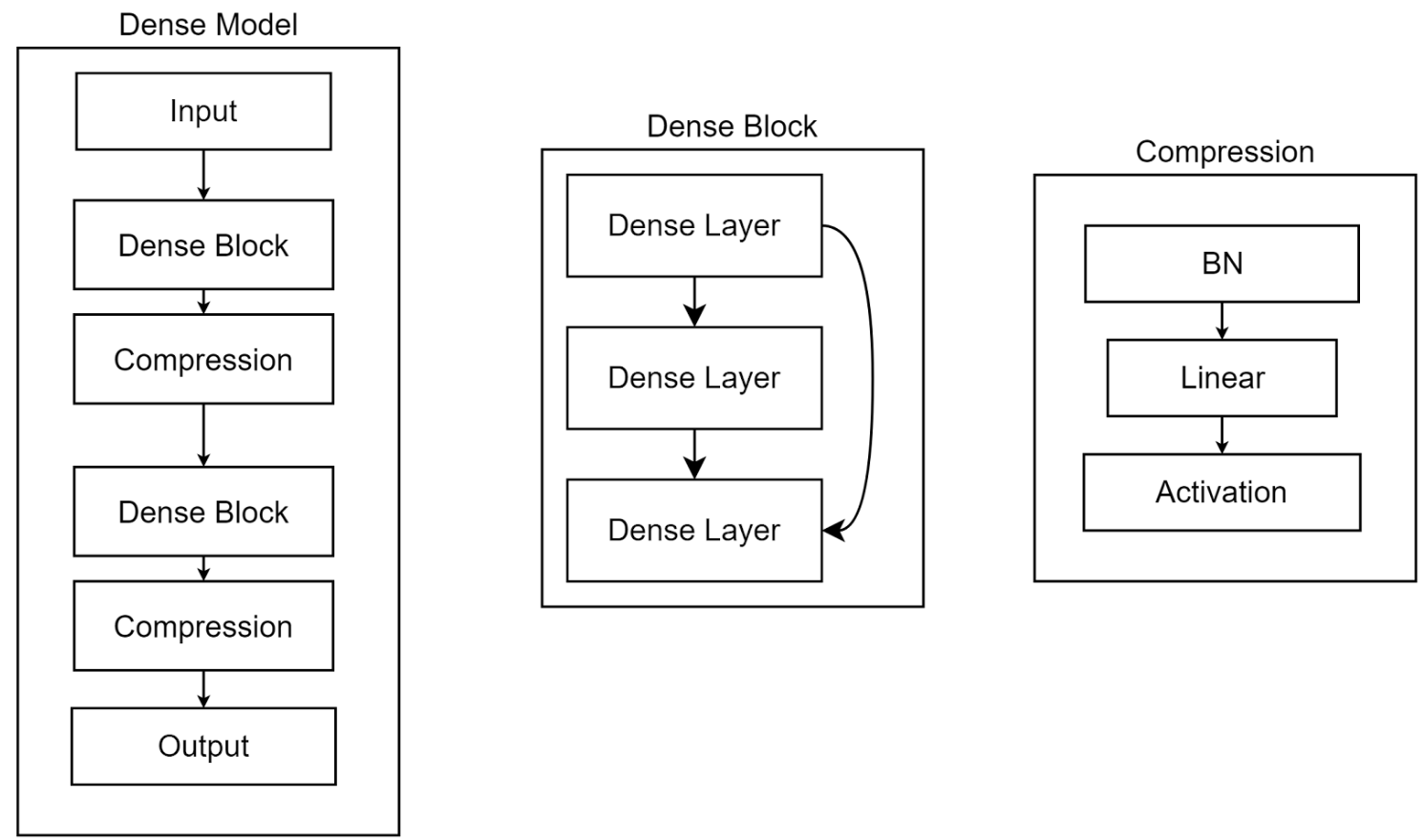
block_config- set number of blocks and layers within each blockcompression- portion of neuron to drop afterDenseBlockgrowth_size- output dim of everyDenseLayerbn_factor- size of intermediate fc is increased times this factor in layer
1.4 Resnet ("resnet")
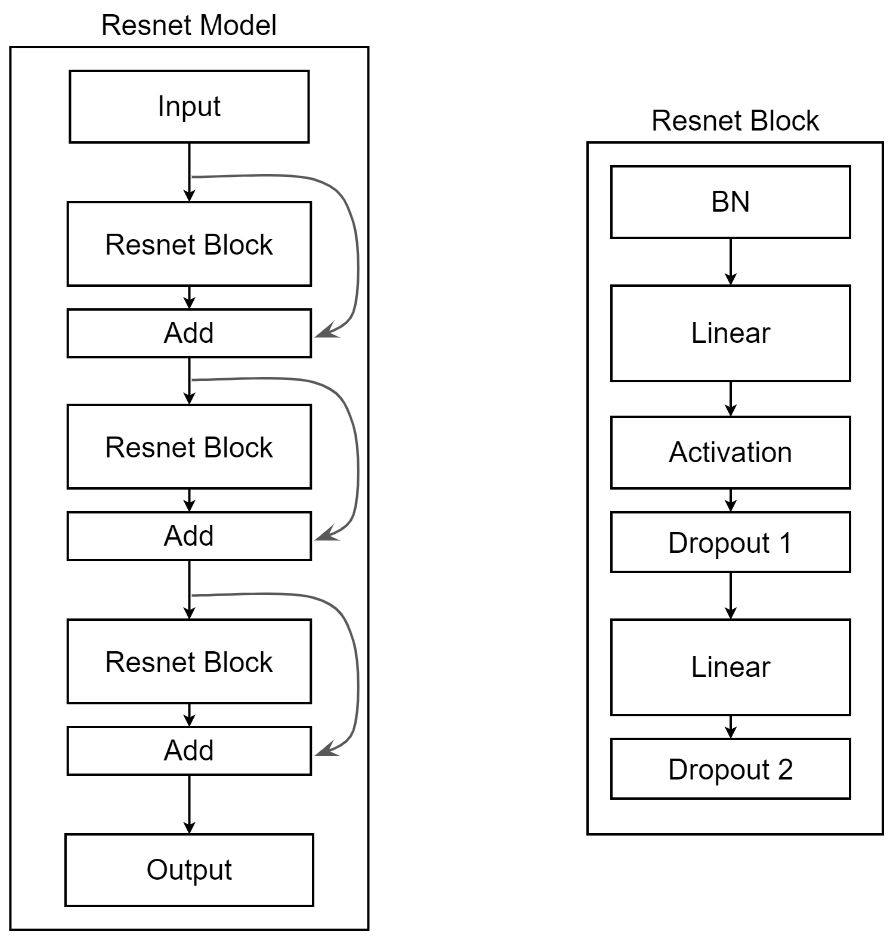
hid_factor- size of intermediate fc is increased times this factor in layer
1.5 SNN ("snn")
hidden_size- define hidden layer dimensions
1.5 NODE ("node")
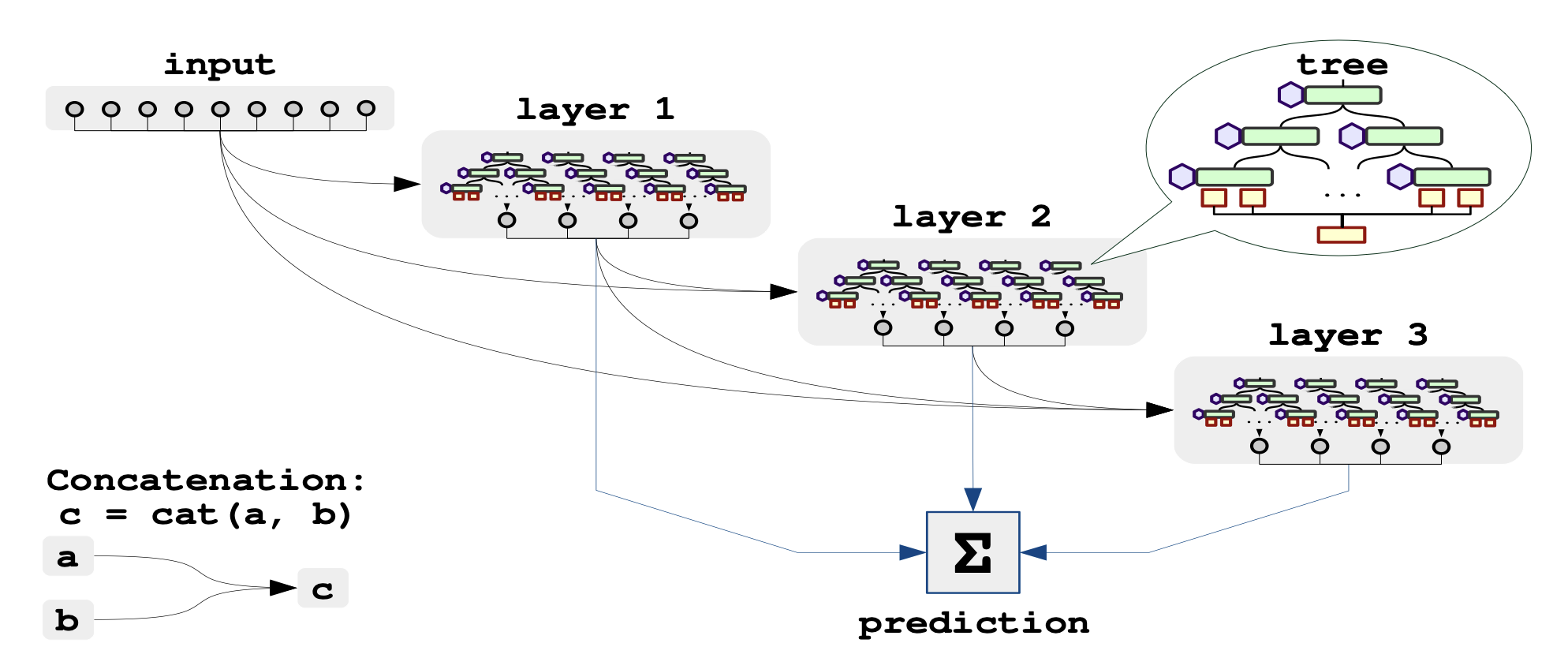
1.5 AutoInt ("autoint")
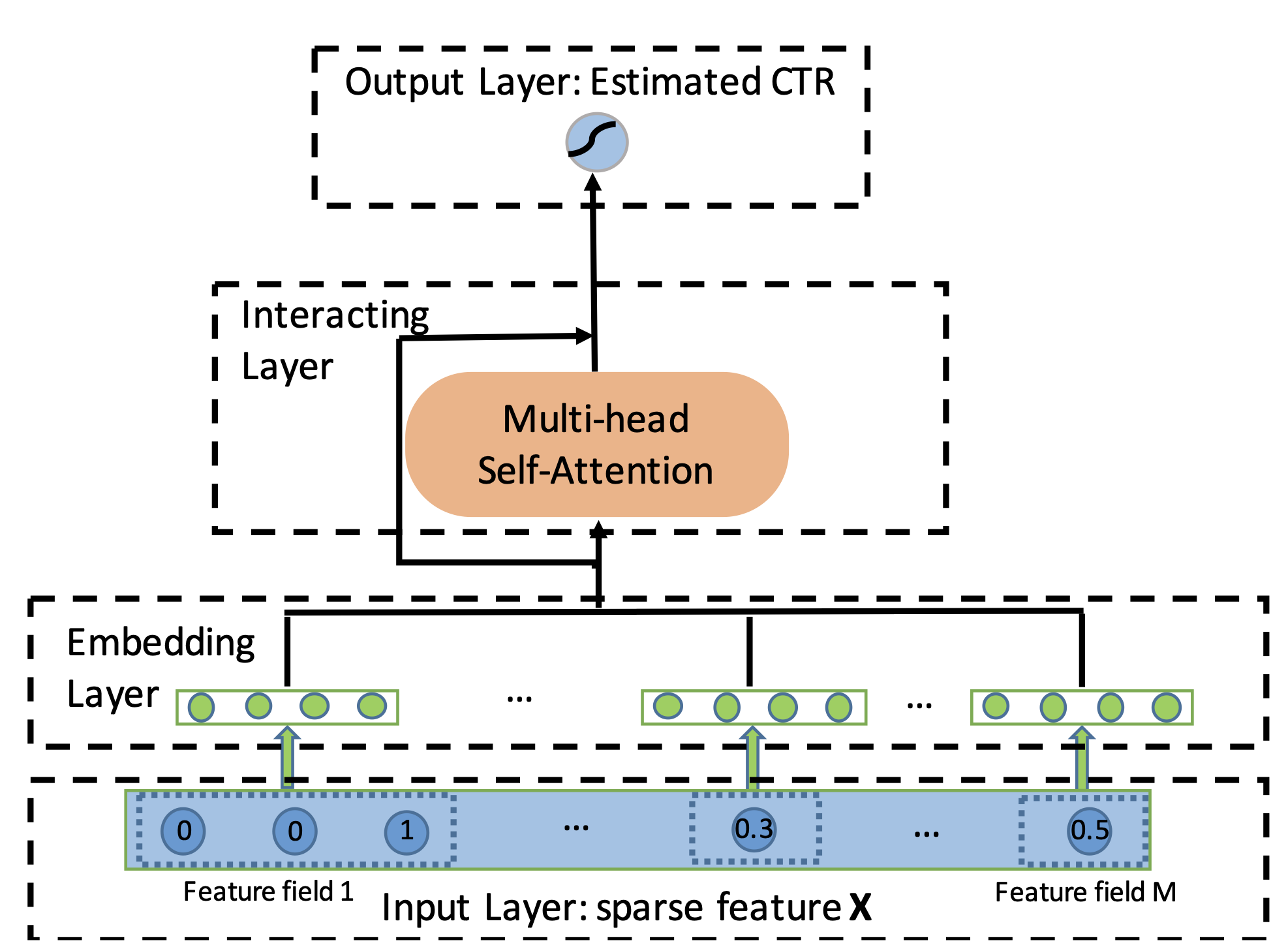
1.5 FTTransformer ("fttransformer")
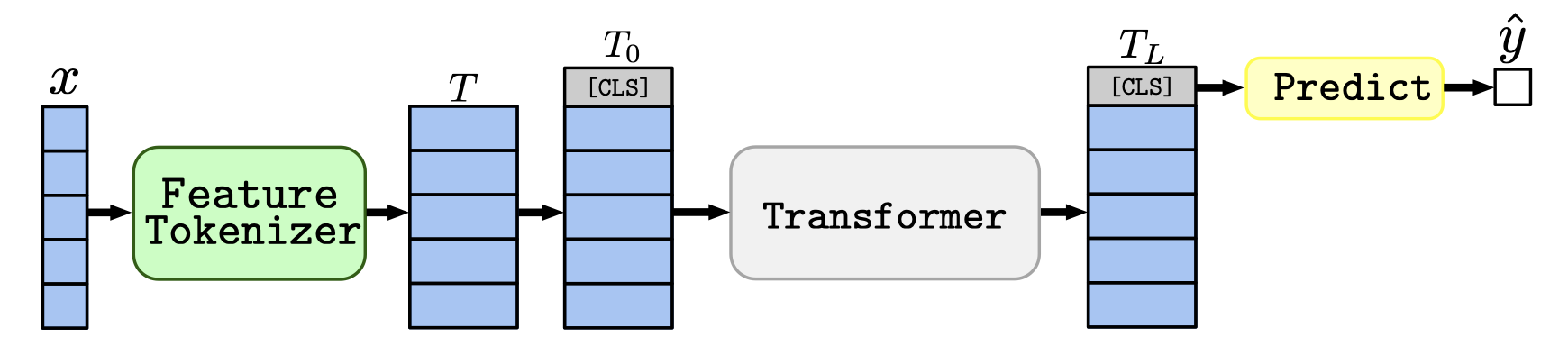
pooling- Pooling used for the last step.n_out- Output dimension, 1 for binary prediction.embedding_size- Embeddings size.depth- Number of Attention Blocks inside Transformer.heads- Number of heads in Attention.attn_dropout- Post-Attention dropout.ff_dropout- Feed-Forward Dropout.dim_head- Attention head dimensionreturn_attn- Return attention scores or not.num_enc_layers- Number of Transformer layers.device- Device to compute on.
2. Example of usage
2.1 Task definition
[5]:
task = Task('binary')
roles = {
'target': TARGET_NAME,
'drop': ['SK_ID_CURR']
}
2.2 LightAutoML model creation - TabularAutoML preset with neural network
In next the cell we are going to create LightAutoML model with TabularAutoML class.
in just several lines. Let’s discuss the params we can setup:
task- the type of the ML task (the only must have parameter)timeout- time limit in seconds for model to traincpu_limit- vCPU count for model to usenn_params- network and training params, for example,"hidden_size","batch_size","lr", etc.nn_pipeline_params- data preprocessing params, which affect how data is fed to the model: use embeddings or target encoding for categorical columns, standard scalar or quantile transformer for numerical columnsreader_params- parameter change for Reader object inside preset, which works on the first step of data preparation: automatic feature typization, preliminary almost-constant features, correct CV setup etc.
[6]:
automl = TabularAutoML(
task = task,
timeout = TIMEOUT,
cpu_limit = N_THREADS,
general_params = {"use_algos": [["mlp"]]}, # ['nn', 'mlp', 'dense', 'denselight', 'resnet', 'snn', 'node', 'autoint', 'fttransformer'] or custom torch model
nn_params = {"n_epochs": 10, "bs": 512, "num_workers": 0, "path_to_save": None, "freeze_defaults": True},
nn_pipeline_params = {"use_qnt": True, "use_te": False},
reader_params = {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE}
)
2.3 AutoML training
To run autoML training use fit_predict method:
train_data- Dataset to train.roles- Roles dict.verbose- Controls the verbosity: the higher, the more messages. <1 : messages are not displayed; >=1 : the computation process for layers is displayed; >=2 : the information about folds processing is also displayed; >=3 : the hyperparameters optimization process is also displayed; >=4 : the training process for every algorithm is displayed;
Note: out-of-fold prediction is calculated during training and returned from the fit_predict method
[7]:
%%time
oof_pred = automl.fit_predict(tr_data, roles = roles, verbose = 1)
[14:56:04] Stdout logging level is INFO.
[14:56:04] Copying TaskTimer may affect the parent PipelineTimer, so copy will create new unlimited TaskTimer
[14:56:04] Task: binary
[14:56:04] Start automl preset with listed constraints:
[14:56:04] - time: 300.00 seconds
[14:56:04] - CPU: 4 cores
[14:56:04] - memory: 16 GB
[14:56:04] Train data shape: (8000, 122)
[14:56:08] Layer 1 train process start. Time left 296.45 secs
[14:56:08] Start fitting Lvl_0_Pipe_0_Mod_0_TorchNN_mlp_0 ...
[14:56:15] Fitting Lvl_0_Pipe_0_Mod_0_TorchNN_mlp_0 finished. score = 0.6035621265821923
[14:56:15] Lvl_0_Pipe_0_Mod_0_TorchNN_mlp_0 fitting and predicting completed
[14:56:15] Time left 289.10 secs
[14:56:15] Layer 1 training completed.
[14:56:15] Automl preset training completed in 10.90 seconds
[14:56:15] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN_mlp_0)
CPU times: user 10.9 s, sys: 822 ms, total: 11.8 s
Wall time: 10.9 s
2.4 Prediction on holdout and model evaluation
[8]:
%%time
te_pred = automl.predict(te_data)
print(f'Prediction for te_data:\n{te_pred}\nShape = {te_pred.shape}')
Prediction for te_data:
array([[0.09815434],
[0.08660936],
[0.060364 ],
...,
[0.09103375],
[0.05593849],
[0.09817966]], dtype=float32)
Shape = (2000, 1)
CPU times: user 1.39 s, sys: 59.4 ms, total: 1.45 s
Wall time: 1.35 s
[9]:
print(f'OOF score: {roc_auc_score(tr_data[TARGET_NAME].values, oof_pred.data[:, 0])}')
print(f'HOLDOUT score: {roc_auc_score(te_data[TARGET_NAME].values, te_pred.data[:, 0])}')
OOF score: 0.6035621265821923
HOLDOUT score: 0.5970482336956522
You can obtain the description of the resulting pipeline:
[10]:
print(automl.create_model_str_desc())
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN_mlp_0)
3. Main training loop and pipeline params
3.1 Training loop params
bs- batch_sizesnap_params- early stopping and checkpoint averaging params, stochastic weight averaging (swa)opt- lr optimizeropt_params- optimizer paramsclip_grad- use grad clipping for regularizationclip_grad_paramsemb_dropout- embedding dropout for categorical columns
This set of params should be passed in nn_params as well.
3.2 Pipeline params
Transformation for numerical columns
use_qnt- uses quantile transformation for numerical columnsoutput_distribution- type of distribuiton of feature after qnt transformern_quantiles- number of quantiles used to build feature distributionqnt_factor- decresesn_quantilesdepending on train data shape
Transformation for categorical columns
use_te- uses target encodingtop_intersections- number of intersections of cat columns to use
Full list of default parametres you can find here:
4. More use cases
Let’s remember default Lama params to be more compact.
[11]:
default_lama_params = {
"task": task,
"timeout": TIMEOUT,
"cpu_limit": N_THREADS,
"reader_params": {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE}
}
default_nn_params = {
"bs": 512, "num_workers": 0, "path_to_save": None, "n_epochs": 10, "freeze_defaults": True
}
4.1 Custom model
Consider simple neural network that we want to train.
[12]:
class SimpleNet(nn.Module):
def __init__(
self,
n_in,
n_out,
hidden_size,
drop_rate,
**kwargs, # kwargs is must-have to hold unnecessary parameters
):
super(SimpleNet, self).__init__()
self.features = nn.Sequential(OrderedDict([]))
self.features.add_module("norm", nn.BatchNorm1d(n_in))
self.features.add_module("dense1", nn.Linear(n_in, hidden_size))
self.features.add_module("act", nn.SiLU())
self.features.add_module("dropout", nn.Dropout(p=drop_rate))
self.features.add_module("dense2", nn.Linear(hidden_size, n_out))
def forward(self, x):
"""
Args:
x: data after feature pipeline transformation
(by default concatenation of columns)
"""
for layer in self.features:
x = layer(x)
return x
[13]:
automl = TabularAutoML(
**default_lama_params,
general_params={"use_algos": [[SimpleNet]]},
nn_params={
**default_nn_params,
"hidden_size": 256,
"drop_rate": 0.1
},
)
automl.fit_predict(tr_data, roles=roles, verbose=1)
[14:56:17] Stdout logging level is INFO.
[14:56:17] Task: binary
[14:56:17] Start automl preset with listed constraints:
[14:56:17] - time: 300.00 seconds
[14:56:17] - CPU: 4 cores
[14:56:17] - memory: 16 GB
[14:56:17] Train data shape: (8000, 122)
[14:56:17] Layer 1 train process start. Time left 299.22 secs
[14:56:18] Start fitting Lvl_0_Pipe_0_Mod_0_TorchNN_0 ...
[14:56:23] Fitting Lvl_0_Pipe_0_Mod_0_TorchNN_0 finished. score = 0.70579837612218
[14:56:23] Lvl_0_Pipe_0_Mod_0_TorchNN_0 fitting and predicting completed
[14:56:23] Time left 293.15 secs
[14:56:23] Layer 1 training completed.
[14:56:23] Automl preset training completed in 6.86 seconds
[14:56:23] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN_0)
[13]:
array([[0.04888836],
[0.02840128],
[0.04246276],
...,
[0.05778075],
[0.17132443],
[0.20606528]], dtype=float32)
4.1.1 Define the pipeline by yourself
[14]:
from typing import Sequence
from typing import Dict
from typing import Optional
from typing import Any
from typing import Callable
from typing import Union
class CatEmbedder(nn.Module):
"""Category data model.
Args:
cat_dims: Sequence with number of unique categories
for category features
"""
def __init__(
self,
cat_dims: Sequence[int],
**kwargs
):
super(CatEmbedder, self).__init__()
emb_dims = [
(int(x), 5)
for x in cat_dims
]
self.no_of_embs = sum([y for x, y in emb_dims])
self.emb_layers = nn.ModuleList([nn.Embedding(x, y) for x, y in emb_dims])
def get_out_shape(self) -> int:
"""Output shape.
Returns:
Int with module output shape.
"""
return self.no_of_embs
def forward(self, inp: Dict[str, torch.Tensor]) -> torch.Tensor:
"""Concat all categorical embeddings
"""
output = torch.cat(
[
emb_layer(inp["cat"][:, i])
for i, emb_layer in enumerate(self.emb_layers)
],
dim=1,
)
return output
class ContEmbedder(nn.Module):
"""Numeric data model.
Class for working with numeric data.
Args:
num_dims: Sequence with number of numeric features.
input_bn: Use 1d batch norm for input data.
"""
def __init__(self, num_dims: int, **kwargs):
super(ContEmbedder, self).__init__()
self.n_out = num_dims
def get_out_shape(self) -> int:
"""Output shape.
Returns:
int with module output shape.
"""
return self.n_out
def forward(self, inp: Dict[str, torch.Tensor]) -> torch.Tensor:
"""Forward-pass."""
return (inp["cont"] - inp["cont"].mean(axis=0)) / (inp["cont"].std(axis=0) + 1e-6)
[15]:
from lightautoml.text.nn_model import TorchUniversalModel
class SimpleNet_plus(TorchUniversalModel):
"""Mixed data model.
Class for preparing input for DL model with mixed data.
Args:
n_out: Number of output dimensions.
cont_params: Dict with numeric model params.
cat_params: Dict with category model para
**kwargs: Loss, task and other parameters.
"""
def __init__(
self,
n_out: int = 1,
cont_params: Optional[Dict] = None,
cat_params: Optional[Dict] = None,
**kwargs,
):
# init parent class (need some helper functions to be used)
super(SimpleNet_plus, self).__init__(**{
**kwargs,
"cont_params": cont_params,
"cat_params": cat_params,
"torch_model": None, # dont need any model inside parent class
})
n_in = 0
# add cont columns processing
self.cont_embedder = ContEmbedder(**cont_params)
n_in += self.cont_embedder.get_out_shape()
# add cat columns processing
self.cat_embedder = CatEmbedder(**cat_params)
n_in += self.cat_embedder.get_out_shape()
self.torch_model = SimpleNet(
**{
**kwargs,
**{"n_in": n_in, "n_out": n_out},
}
)
def get_logits(self, inp: Dict[str, torch.Tensor]) -> torch.Tensor:
outputs = []
outputs.append(self.cont_embedder(inp))
outputs.append(self.cat_embedder(inp))
if len(outputs) > 1:
output = torch.cat(outputs, dim=1)
else:
output = outputs[0]
logits = self.torch_model(output)
return logits
[16]:
automl = TabularAutoML(
**default_lama_params,
general_params={"use_algos": [[SimpleNet_plus]]},
nn_params={
**default_nn_params,
"hidden_size": 256,
"drop_rate": 0.1,
"model_with_emb": True,
},
debug=True
)
automl.fit_predict(tr_data, roles = roles, verbose = 1)
[14:56:24] Stdout logging level is INFO.
[14:56:24] Task: binary
[14:56:24] Start automl preset with listed constraints:
[14:56:24] - time: 300.00 seconds
[14:56:24] - CPU: 4 cores
[14:56:24] - memory: 16 GB
[14:56:24] Train data shape: (8000, 122)
[14:56:24] Layer 1 train process start. Time left 299.21 secs
[14:56:25] Start fitting Lvl_0_Pipe_0_Mod_0_TorchNN_0 ...
[14:56:30] Fitting Lvl_0_Pipe_0_Mod_0_TorchNN_0 finished. score = 0.6600159152016962
[14:56:30] Lvl_0_Pipe_0_Mod_0_TorchNN_0 fitting and predicting completed
[14:56:30] Time left 293.19 secs
[14:56:30] Layer 1 training completed.
[14:56:30] Automl preset training completed in 6.82 seconds
[14:56:30] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_TorchNN_0)
[16]:
array([[0.07509199],
[0.06439159],
[0.04291169],
...,
[0.11671165],
[0.2381251 ],
[0.04382631]], dtype=float32)
4.2 Tuning network
One can try optimize metric with the help of Optuna. Among validation stratagies there are:
fit_on_holdout = True- holdoutfit_on_holdout = False- cross-validation.
4.2.1 Built-in models
Use "_tuned" in model name to tune it.
[17]:
automl = TabularAutoML(
**default_lama_params,
general_params={"use_algos": [["denselight_tuned"]]},
nn_params={
**default_nn_params,
"n_epochs": 3,
"tuning_params": {
"max_tuning_iter": 5,
"max_tuning_time": 100,
"fit_on_holdout": True
}
},
)
automl.fit_predict(tr_data, roles = roles, verbose = 3)
[14:56:31] Stdout logging level is INFO3.
[14:56:31] Task: binary
[14:56:31] Start automl preset with listed constraints:
[14:56:31] - time: 300.00 seconds
[14:56:31] - CPU: 4 cores
[14:56:31] - memory: 16 GB
[14:56:31] Train data shape: (8000, 122)
[14:56:31] Feats was rejected during automatic roles guess: []
[14:56:31] Layer 1 train process start. Time left 299.23 secs
[14:56:31] Start hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 ... Time budget is 100.00 secs
[14:56:32] Epoch: 0, train loss: 0.307483434677124, val loss: 0.2785775661468506, val metric: 0.6090575236140289
[14:56:32] Epoch: 1, train loss: 0.27614495158195496, val loss: 0.2799951434135437, val metric: 0.585088014710992
[14:56:32] Epoch: 2, train loss: 0.27499067783355713, val loss: 0.28620871901512146, val metric: 0.626435952125129
[14:56:32] Early stopping: val loss: 0.27636581659317017, val metric: 0.6215073421321315
[14:56:33] Trial 1 with hyperparameters {'bs': 128, 'weight_decay_bin': 0, 'lr': 0.029154431891537533} scored 0.6215073421321315 in 0:00:01.209556
[14:56:33] Epoch: 0, train loss: 0.275651752948761, val loss: 0.30943918228149414, val metric: 0.5956214485409284
[14:56:33] Epoch: 1, train loss: 0.28080031275749207, val loss: 0.3092973828315735, val metric: 0.590257175083257
[14:56:33] Epoch: 2, train loss: 0.27882617712020874, val loss: 0.3090418577194214, val metric: 0.5908826060693533
[14:56:33] Early stopping: val loss: 0.30920112133026123, val metric: 0.5908826060693533
[14:56:33] Trial 2 with hyperparameters {'bs': 512, 'weight_decay_bin': 0, 'lr': 5.415244119402538e-05} scored 0.5908826060693533 in 0:00:00.625572
[14:56:33] Epoch: 0, train loss: 0.2746148705482483, val loss: 0.2774512767791748, val metric: 0.5961372954653581
[14:56:33] Epoch: 1, train loss: 0.27803024649620056, val loss: 0.276823490858078, val metric: 0.5987940407652709
[14:56:34] Epoch: 2, train loss: 0.2752102017402649, val loss: 0.2738468050956726, val metric: 0.6048131458109488
[14:56:34] Early stopping: val loss: 0.2762503921985626, val metric: 0.6007344804913642
[14:56:34] Trial 3 with hyperparameters {'bs': 1024, 'weight_decay_bin': 1, 'weight_decay': 2.9204338471814107e-05, 'lr': 0.0006672367170464204} scored 0.6007344804913642 in 0:00:00.504866
[14:56:34] Epoch: 0, train loss: 0.2786032557487488, val loss: 0.2767927944660187, val metric: 0.5910777191547594
[14:56:35] Epoch: 1, train loss: 0.27806466817855835, val loss: 0.27634257078170776, val metric: 0.592954012113048
[14:56:35] Epoch: 2, train loss: 0.2776066064834595, val loss: 0.2759130001068115, val metric: 0.5941113267155251
[14:56:35] Early stopping: val loss: 0.27634990215301514, val metric: 0.593207926402275
[14:56:36] Trial 4 with hyperparameters {'bs': 64, 'weight_decay_bin': 0, 'lr': 1.8205657658407255e-05} scored 0.593207926402275 in 0:00:01.881862
[14:56:36] Epoch: 0, train loss: 0.27860182523727417, val loss: 0.28250277042388916, val metric: 0.5923793639847972
[14:56:36] Epoch: 1, train loss: 0.2779836356639862, val loss: 0.2820056080818176, val metric: 0.5916817678849207
[14:56:37] Epoch: 2, train loss: 0.2774103283882141, val loss: 0.2815183401107788, val metric: 0.5948837607111739
[14:56:37] Early stopping: val loss: 0.2820083796977997, val metric: 0.5934698590374777
[14:56:37] Trial 5 with hyperparameters {'bs': 128, 'weight_decay_bin': 0, 'lr': 3.077180271250682e-05} scored 0.5934698590374777 in 0:00:01.121957
[14:56:37] Hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 completed
[14:56:37] The set of hyperparameters {'bs': 128, 'weight_decay_bin': 0, 'lr': 0.029154431891537533}
achieve 0.6215 auc
[14:56:37] Start fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 ...
[14:56:37] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 =====
[14:56:37] Epoch: 0, train loss: 0.2774243652820587, val loss: 0.2794122099876404, val metric: 0.5975324876651111
[14:56:37] Epoch: 1, train loss: 0.2743901014328003, val loss: 0.2776646912097931, val metric: 0.608838355490696
[14:56:38] Epoch: 2, train loss: 0.27337446808815, val loss: 0.2764543294906616, val metric: 0.6192034040551448
[14:56:38] Early stopping: val loss: 0.2777901291847229, val metric: 0.6107948319087405
[14:56:38] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 =====
[14:56:38] Epoch: 0, train loss: 0.27729275822639465, val loss: 0.27042776346206665, val metric: 0.6243578040081522
[14:56:39] Epoch: 1, train loss: 0.2746446132659912, val loss: 0.268259733915329, val metric: 0.6331256368885869
[14:56:39] Epoch: 2, train loss: 0.2735038101673126, val loss: 0.26757094264030457, val metric: 0.6373237941576086
[14:56:39] Early stopping: val loss: 0.2686738669872284, val metric: 0.6330725628396741
[14:56:39] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 =====
[14:56:39] Epoch: 0, train loss: 0.2761422395706177, val loss: 0.27418816089630127, val metric: 0.5687123174252717
[14:56:40] Epoch: 1, train loss: 0.2733106017112732, val loss: 0.2741503119468689, val metric: 0.5761931046195653
[14:56:40] Epoch: 2, train loss: 0.27197468280792236, val loss: 0.2742484509944916, val metric: 0.5801471212635869
[14:56:40] Early stopping: val loss: 0.2739076316356659, val metric: 0.5770820949388586
[14:56:40] ===== Start working with fold 3 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 =====
[14:56:41] Epoch: 0, train loss: 0.2768873870372772, val loss: 0.27838170528411865, val metric: 0.6020985478940217
[14:56:41] Epoch: 1, train loss: 0.2738708257675171, val loss: 0.2780988812446594, val metric: 0.5976827870244564
[14:56:41] Epoch: 2, train loss: 0.2721073031425476, val loss: 0.2787047028541565, val metric: 0.5934050186820653
[14:56:41] Early stopping: val loss: 0.2780289649963379, val metric: 0.5992405103600543
[14:56:41] ===== Start working with fold 4 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 =====
[14:56:42] Epoch: 0, train loss: 0.27685776352882385, val loss: 0.27540671825408936, val metric: 0.5904859459918478
[14:56:42] Epoch: 1, train loss: 0.27350443601608276, val loss: 0.2741386592388153, val metric: 0.5980489979619567
[14:56:42] Epoch: 2, train loss: 0.27244144678115845, val loss: 0.27352553606033325, val metric: 0.6023214588994564
[14:56:42] Early stopping: val loss: 0.2742116153240204, val metric: 0.5989326808763588
[14:56:43] Fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 finished. score = 0.6015718759719786
[14:56:43] Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0 fitting and predicting completed
[14:56:43] Time left 288.04 secs
[14:56:43] Layer 1 training completed.
[14:56:43] Automl preset training completed in 11.97 seconds
[14:56:43] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_denselight_tuned_0)
[17]:
array([[0.07784943],
[0.04554275],
[0.05328501],
...,
[0.07100379],
[0.09577154],
[0.07620702]], dtype=float32)
4.2.2 Custom model
There is a spesial flag tuned to mark that you need optimize parameters for the model.
[18]:
automl = TabularAutoML(
**default_lama_params,
general_params={"use_algos": [[SimpleNet]]},
nn_params={
**default_nn_params,
"hidden_size": 256,
"drop_rate": 0.1,
"tuned": True,
"tuning_params": {
"max_tuning_iter": 5,
"max_tuning_time": 100,
"fit_on_holdout": True
}
},
)
automl.fit_predict(tr_data, roles = roles, verbose = 2)
[14:56:43] Stdout logging level is INFO2.
[14:56:43] Task: binary
[14:56:43] Start automl preset with listed constraints:
[14:56:43] - time: 300.00 seconds
[14:56:43] - CPU: 4 cores
[14:56:43] - memory: 16 GB
[14:56:43] Train data shape: (8000, 122)
[14:56:43] Layer 1 train process start. Time left 299.22 secs
[14:56:43] Start hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 ... Time budget is 100.00 secs
Optimization Progress: 100%|████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:12<00:00, 2.42s/it, best_trial=0, best_value=0.767]
[14:56:56] Hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 completed
[14:56:56] The set of hyperparameters {'bs': 128, 'weight_decay_bin': 0, 'lr': 0.029154431891537533}
achieve 0.7667 auc
[14:56:56] Start fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 ...
[14:56:56] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:56:58] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:01] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:04] ===== Start working with fold 3 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:06] ===== Start working with fold 4 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:09] Fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 finished. score = 0.7271980081974132
[14:57:09] Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 fitting and predicting completed
[14:57:09] Time left 273.65 secs
[14:57:09] Layer 1 training completed.
[14:57:09] Automl preset training completed in 26.35 seconds
[14:57:09] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0)
[18]:
array([[0.03879727],
[0.02351108],
[0.0386253 ],
...,
[0.04145308],
[0.182652 ],
[0.28383675]], dtype=float32)
optimization_search_space which describes necessary parameter grid. See example below.bsin[64, 128, 256, 512, 1024]hidden_sizein[64, 128, 256, 512, 1024]drop_ratein[0.0, 0.3]
[19]:
def my_opt_space(trial: optuna.trial.Trial, estimated_n_trials, suggested_params):
'''
This function needs for parameter tuning
'''
# optionally
trial_values = copy(suggested_params)
trial_values["bs"] = trial.suggest_categorical(
"bs", [2 ** i for i in range(6, 11)]
)
trial_values["hidden_size"] = trial.suggest_categorical(
"hidden_size", [2 ** i for i in range(6, 11)]
)
trial_values["drop_rate"] = trial.suggest_float(
"drop_rate", 0.0, 0.3
)
return trial_values
[20]:
automl = TabularAutoML(
**default_lama_params,
general_params={"use_algos": [[SimpleNet]]},
nn_params={
**default_nn_params,
"n_epochs": 3,
"tuned": True,
"tuning_params": {
"max_tuning_iter": 5,
"max_tuning_time": 3600,
"fit_on_holdout": True
},
"optimization_search_space": my_opt_space,
},
)
automl.fit_predict(tr_data, roles = roles, verbose = 3)
[14:57:09] Stdout logging level is INFO3.
[14:57:09] Task: binary
[14:57:09] Start automl preset with listed constraints:
[14:57:09] - time: 300.00 seconds
[14:57:09] - CPU: 4 cores
[14:57:09] - memory: 16 GB
[14:57:09] Train data shape: (8000, 122)
[14:57:10] Feats was rejected during automatic roles guess: []
[14:57:10] Layer 1 train process start. Time left 299.19 secs
[14:57:10] Start hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 ... Time budget is 156.97 secs
[14:57:10] Epoch: 0, train loss: 0.27667880058288574, val loss: 0.2776942551136017, val metric: 0.6380251348418515
[14:57:10] Epoch: 1, train loss: 0.2685483694076538, val loss: 0.2682102620601654, val metric: 0.6962383266246506
[14:57:11] Epoch: 2, train loss: 0.2586376965045929, val loss: 0.259479820728302, val metric: 0.741352213865324
[14:57:11] Early stopping: val loss: 0.2688170075416565, val metric: 0.7005254689396005
[14:57:11] Trial 1 with hyperparameters {'bs': 128, 'hidden_size': 256, 'drop_rate': 0.006175348288740734} scored 0.7005254689396005 in 0:00:01.061573
[14:57:11] Epoch: 0, train loss: 0.2708968222141266, val loss: 0.2574772536754608, val metric: 0.73635678432253
[14:57:12] Epoch: 1, train loss: 0.2547965347766876, val loss: 0.2453528791666031, val metric: 0.7694297886898558
[14:57:12] Epoch: 2, train loss: 0.244949072599411, val loss: 0.24259500205516815, val metric: 0.7720972251177362
[14:57:12] Early stopping: val loss: 0.2467520385980606, val metric: 0.7681415077697773
[14:57:13] Trial 2 with hyperparameters {'bs': 64, 'hidden_size': 1024, 'drop_rate': 0.04184815819561255} scored 0.7681415077697773 in 0:00:01.623261
[14:57:13] Epoch: 0, train loss: 0.2758210599422455, val loss: 0.30738407373428345, val metric: 0.6267513404001689
[14:57:13] Epoch: 1, train loss: 0.27457138895988464, val loss: 0.30406495928764343, val metric: 0.6331232526687729
[14:57:13] Epoch: 2, train loss: 0.27020180225372314, val loss: 0.30057811737060547, val metric: 0.6501381828289794
[14:57:13] Early stopping: val loss: 0.30382469296455383, val metric: 0.6392439234301416
[14:57:13] Trial 3 with hyperparameters {'bs': 512, 'hidden_size': 512, 'drop_rate': 0.019515477895583853} scored 0.6392439234301416 in 0:00:00.557979
[14:57:13] Epoch: 0, train loss: 0.27815869450569153, val loss: 0.28139299154281616, val metric: 0.6253187292525297
[14:57:14] Epoch: 1, train loss: 0.2752159833908081, val loss: 0.2780429720878601, val metric: 0.6364214656467331
[14:57:14] Epoch: 2, train loss: 0.2704654037952423, val loss: 0.27340632677078247, val metric: 0.6653997680025231
[14:57:14] Early stopping: val loss: 0.2779545187950134, val metric: 0.6449262579448445
[14:57:14] Trial 4 with hyperparameters {'bs': 128, 'hidden_size': 64, 'drop_rate': 0.2727961206236346} scored 0.6449262579448445 in 0:00:01.034966
[14:57:15] Epoch: 0, train loss: 0.27770310640335083, val loss: 0.28032609820365906, val metric: 0.627515756049842
[14:57:15] Epoch: 1, train loss: 0.27274399995803833, val loss: 0.27464091777801514, val metric: 0.6614868151664342
[14:57:15] Epoch: 2, train loss: 0.2659642994403839, val loss: 0.26697367429733276, val metric: 0.7082605000240552
[14:57:15] Early stopping: val loss: 0.27455854415893555, val metric: 0.6712371238727542
[14:57:15] Trial 5 with hyperparameters {'bs': 128, 'hidden_size': 128, 'drop_rate': 0.17936999364332554} scored 0.6712371238727542 in 0:00:01.005326
[14:57:15] Hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 completed
[14:57:15] The set of hyperparameters {'bs': 64, 'hidden_size': 1024, 'drop_rate': 0.04184815819561255}
achieve 0.7681 auc
[14:57:15] Start fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 ...
[14:57:15] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:16] Epoch: 0, train loss: 0.2708968222141266, val loss: 0.2574772536754608, val metric: 0.73635678432253
[14:57:16] Epoch: 1, train loss: 0.2547965347766876, val loss: 0.2453528791666031, val metric: 0.7694297886898558
[14:57:17] Epoch: 2, train loss: 0.244949072599411, val loss: 0.24259500205516815, val metric: 0.7720972251177362
[14:57:17] Early stopping: val loss: 0.2467520385980606, val metric: 0.7681415077697773
[14:57:17] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:17] Epoch: 0, train loss: 0.27157771587371826, val loss: 0.2592219412326813, val metric: 0.7320822010869567
[14:57:18] Epoch: 1, train loss: 0.2547703981399536, val loss: 0.2508712708950043, val metric: 0.742293648097826
[14:57:18] Epoch: 2, train loss: 0.24370187520980835, val loss: 0.2526074945926666, val metric: 0.7376868206521738
[14:57:18] Early stopping: val loss: 0.25174227356910706, val metric: 0.7418584408967391
[14:57:18] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:19] Epoch: 0, train loss: 0.2685704529285431, val loss: 0.27050256729125977, val metric: 0.6421482252038044
[14:57:19] Epoch: 1, train loss: 0.2485620081424713, val loss: 0.2682766616344452, val metric: 0.673721976902174
[14:57:20] Epoch: 2, train loss: 0.2378905713558197, val loss: 0.2720091640949249, val metric: 0.6822032099184783
[14:57:20] Early stopping: val loss: 0.26766759157180786, val metric: 0.6720713739809782
[14:57:20] ===== Start working with fold 3 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:21] Epoch: 0, train loss: 0.2702709436416626, val loss: 0.2615496516227722, val metric: 0.7016389266304347
[14:57:21] Epoch: 1, train loss: 0.2521918714046478, val loss: 0.2561715841293335, val metric: 0.7150401239809783
[14:57:22] Epoch: 2, train loss: 0.24233928322792053, val loss: 0.2551616132259369, val metric: 0.7239884086277175
[14:57:22] Early stopping: val loss: 0.2555495500564575, val metric: 0.7176938264266304
[14:57:22] ===== Start working with fold 4 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 =====
[14:57:22] Epoch: 0, train loss: 0.2711535096168518, val loss: 0.2612263262271881, val metric: 0.701416015625
[14:57:23] Epoch: 1, train loss: 0.25223615765571594, val loss: 0.254193514585495, val metric: 0.7256443189538043
[14:57:23] Epoch: 2, train loss: 0.24515873193740845, val loss: 0.25219428539276123, val metric: 0.7378141983695652
[14:57:23] Early stopping: val loss: 0.25415900349617004, val metric: 0.7281971807065218
[14:57:23] Fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 finished. score = 0.7241582599492865
[14:57:23] Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0 fitting and predicting completed
[14:57:23] Time left 285.60 secs
[14:57:23] Layer 1 training completed.
[14:57:23] Automl preset training completed in 14.40 seconds
[14:57:23] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_0)
[20]:
array([[0.04496425],
[0.03032025],
[0.03665409],
...,
[0.05365612],
[0.16432838],
[0.1691863 ]], dtype=float32)
4.2.3 One more example
Tuning NODE params
[21]:
TIMEOUT = 3000
[22]:
default_lama_params = {
"task": task,
"timeout": TIMEOUT,
"cpu_limit": N_THREADS,
"reader_params": {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE}
}
default_nn_params = {
"bs": 512, "num_workers": 0, "path_to_save": None, "n_epochs": 10, "freeze_defaults": True
}
[23]:
def my_opt_space_NODE(trial: optuna.trial.Trial, estimated_n_trials, suggested_params):
'''
This function needs for parameter tuning
'''
# optionally
trial_values = copy(suggested_params)
trial_values["layer_dim"] = trial.suggest_categorical(
"layer_dim", [2 ** i for i in range(8, 10)]
)
trial_values["use_original_head"] = trial.suggest_categorical(
"use_original_head", [True, False]
)
trial_values["num_layers"] = trial.suggest_int(
"num_layers", 1, 3
)
trial_values["drop_rate"] = trial.suggest_float(
"drop_rate", 0.0, 0.3
)
trial_values["tree_dim"] = trial.suggest_int(
"tree_dim", 1, 3
)
return trial_values
[24]:
automl = TabularAutoML(
task = task,
timeout = TIMEOUT,
cpu_limit = N_THREADS,
general_params = {"use_algos": [["node_tuned"]]}, # ['nn', 'mlp', 'dense', 'denselight', 'resnet', 'snn'] or custom torch model
nn_params = {"n_epochs": 10, "bs": 512, "num_workers": 0, "path_to_save": None, "freeze_defaults": True, "optimization_search_space": my_opt_space_NODE,},
nn_pipeline_params = {"use_qnt": True, "use_te": False},
reader_params = {'n_jobs': N_THREADS, 'cv': N_FOLDS, 'random_state': RANDOM_STATE}
)
[25]:
oof_pred = automl.fit_predict(tr_data, roles = roles, verbose = 2)
[14:57:24] Stdout logging level is INFO2.
[14:57:24] Task: binary
[14:57:24] Start automl preset with listed constraints:
[14:57:24] - time: 3000.00 seconds
[14:57:24] - CPU: 4 cores
[14:57:24] - memory: 16 GB
[14:57:24] Train data shape: (8000, 122)
[14:57:25] Layer 1 train process start. Time left 2999.22 secs
[14:57:25] Start hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 ... Time budget is 1574.34 secs
Optimization Progress: 100%|█████████████████████████████████████████████████████████████████████████████████| 25/25 [03:48<00:00, 9.14s/it, best_trial=13, best_value=0.732]
[15:01:14] Hyperparameters optimization for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 completed
[15:01:14] The set of hyperparameters {'layer_dim': 512, 'use_original_head': False, 'num_layers': 3, 'drop_rate': 0.1310638585198816, 'tree_dim': 3}
achieve 0.7315 auc
[15:01:14] Start fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 ...
[15:01:14] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 =====
[15:01:27] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 =====
[15:01:41] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 =====
[15:01:54] ===== Start working with fold 3 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 =====
[15:02:07] ===== Start working with fold 4 for Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 =====
[15:02:20] Fitting Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 finished. score = 0.6942477367184283
[15:02:20] Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0 fitting and predicting completed
[15:02:20] Time left 2703.48 secs
[15:02:20] Layer 1 training completed.
[15:02:20] Automl preset training completed in 296.53 seconds
[15:02:20] Model description:
Final prediction for new objects (level 0) =
1.00000 * (5 averaged models Lvl_0_Pipe_0_Mod_0_Tuned_TorchNN_node_tuned_0)
4.3 Several models
[26]:
automl = TabularAutoML(
**default_lama_params,
general_params = {"use_algos": [["lgb", "mlp", "dense"]]},
nn_params = {"0": {**default_nn_params, "n_epochs": 2},
"1": {**default_nn_params, "n_epochs": 5}},
)
automl.fit_predict(tr_data, roles = roles, verbose = 3)
[15:02:20] Stdout logging level is INFO3.
[15:02:20] Task: binary
[15:02:20] Start automl preset with listed constraints:
[15:02:20] - time: 3000.00 seconds
[15:02:20] - CPU: 4 cores
[15:02:20] - memory: 16 GB
[15:02:20] Train data shape: (8000, 122)
[15:02:21] Feats was rejected during automatic roles guess: []
[15:02:21] Layer 1 train process start. Time left 2999.21 secs
[15:02:21] Training until validation scores don't improve for 200 rounds
[15:02:24] Selector_LightGBM fitting and predicting completed
[15:02:25] Start fitting Lvl_0_Pipe_0_Mod_0_LightGBM ...
[15:02:25] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_LightGBM =====
[15:02:25] Training until validation scores don't improve for 200 rounds
[15:02:27] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_LightGBM =====
[15:02:27] Training until validation scores don't improve for 200 rounds
[15:02:31] ===== Start working with fold 2 for Lvl_0_Pipe_0_Mod_0_LightGBM =====
[15:02:31] Training until validation scores don't improve for 200 rounds
[15:02:33] ===== Start working with fold 3 for Lvl_0_Pipe_0_Mod_0_LightGBM =====
[15:02:33] Training until validation scores don't improve for 200 rounds
[15:02:37] ===== Start working with fold 4 for Lvl_0_Pipe_0_Mod_0_LightGBM =====
[15:02:37] Training until validation scores don't improve for 200 rounds
[15:02:39] Fitting Lvl_0_Pipe_0_Mod_0_LightGBM finished. score = 0.7324164765495265
[15:02:39] Lvl_0_Pipe_0_Mod_0_LightGBM fitting and predicting completed
[15:02:39] Time left 2981.34 secs
[15:02:39] Start fitting Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 ...
[15:02:39] ===== Start working with fold 0 for Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 =====
[15:02:39] Epoch: 0, train loss: 0.27922049164772034, val loss: 0.30915024876594543, val metric: 0.5770001764036115
[15:02:39] Epoch: 1, train loss: 0.2804635167121887, val loss: 0.30738765001296997, val metric: 0.5919196454821967
[15:02:40] Early stopping: val loss: 0.3083692789077759, val metric: 0.5864190601429403
[15:02:40] ===== Start working with fold 1 for Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 =====
[15:02:40] Epoch: 0, train loss: 0.2781796455383301, val loss: 0.2599707245826721, val metric: 0.6234980044157609
[15:02:40] Epoch: 1, train loss: 0.27900466322898865, val loss: 0.25812670588493347, val metric: 0.6304188603940217
[15:02:40] Early stopping: val loss: 0.259158730506897, val metric: 0.6298456606657609
[15:02:40] ===== Start working with fold 2 for Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 =====
[15:02:40] Epoch: 0, train loss: 0.27802005410194397, val loss: 0.26105043292045593, val metric: 0.54180908203125
[15:02:41] Epoch: 1, train loss: 0.2754856050014496, val loss: 0.26127585768699646, val metric: 0.5531536599864131
[15:02:41] Early stopping: val loss: 0.2610853612422943, val metric: 0.5479577105978262
[15:02:41] ===== Start working with fold 3 for Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 =====
[15:02:41] Epoch: 0, train loss: 0.2771044075489044, val loss: 0.2935408353805542, val metric: 0.5986620032269022
[15:02:41] Epoch: 1, train loss: 0.2794908881187439, val loss: 0.292603075504303, val metric: 0.5987601902173911
[15:02:41] Early stopping: val loss: 0.2930262088775635, val metric: 0.6013183593749999
[15:02:41] ===== Start working with fold 4 for Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 =====
[15:02:41] Epoch: 0, train loss: 0.27787843346595764, val loss: 0.2770363688468933, val metric: 0.5949680494225544
[15:02:41] Epoch: 1, train loss: 0.27761200070381165, val loss: 0.2755982279777527, val metric: 0.5874899159307065
[15:02:41] Early stopping: val loss: 0.27642762660980225, val metric: 0.5912050993546196
[15:02:42] Fitting Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 finished. score = 0.5890259518134635
[15:02:42] Lvl_0_Pipe_1_Mod_0_TorchNN_mlp_0 fitting and predicting completed
[15:02:42] Start fitting Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 ...
[15:02:42] ===== Start working with fold 0 for Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 =====
[15:02:42] Epoch: 0, train loss: 0.27331802248954773, val loss: 0.3054792881011963, val metric: 0.6767831465058721
[15:02:42] Epoch: 1, train loss: 0.24652224779129028, val loss: 0.28541794419288635, val metric: 0.7536603749378579
[15:02:42] Epoch: 2, train loss: 0.22167454659938812, val loss: 0.29559990763664246, val metric: 0.7280871968397026
[15:02:42] Epoch: 3, train loss: 0.18925495445728302, val loss: 0.32088974118232727, val metric: 0.7067904699285298
[15:02:43] Epoch: 4, train loss: 0.15982066094875336, val loss: 0.3512553572654724, val metric: 0.7054808067525163
[15:02:43] Early stopping: val loss: 0.2940850555896759, val metric: 0.733935243837901
[15:02:43] ===== Start working with fold 1 for Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 =====
[15:02:43] Epoch: 0, train loss: 0.2741259038448334, val loss: 0.2579110264778137, val metric: 0.714859672214674
[15:02:43] Epoch: 1, train loss: 0.24377931654453278, val loss: 0.2441163808107376, val metric: 0.7128348972486412
[15:02:43] Epoch: 2, train loss: 0.21424879133701324, val loss: 0.2476673424243927, val metric: 0.6905942170516304
[15:02:44] Epoch: 3, train loss: 0.18909378349781036, val loss: 0.2624853551387787, val metric: 0.6963155995244565
[15:02:44] Epoch: 4, train loss: 0.15743489563465118, val loss: 0.2790760099887848, val metric: 0.6850798233695653
[15:02:44] Early stopping: val loss: 0.24882426857948303, val metric: 0.7349694293478262
[15:02:44] ===== Start working with fold 2 for Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 =====
[15:02:44] Epoch: 0, train loss: 0.2707020044326782, val loss: 0.2598980665206909, val metric: 0.6082498301630435
[15:02:44] Epoch: 1, train loss: 0.2435956597328186, val loss: 0.2571799159049988, val metric: 0.6500668733016304
[15:02:45] Epoch: 2, train loss: 0.21632780134677887, val loss: 0.2744308412075043, val metric: 0.630631156589674
[15:02:45] Epoch: 3, train loss: 0.18905353546142578, val loss: 0.2583690583705902, val metric: 0.6252043350883152
[15:02:45] Epoch: 4, train loss: 0.1545938104391098, val loss: 0.31239771842956543, val metric: 0.6080746858016305
[15:02:45] Early stopping: val loss: 0.25516635179519653, val metric: 0.6447541610054348
[15:02:45] ===== Start working with fold 3 for Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 =====
[15:02:45] Epoch: 0, train loss: 0.27545467019081116, val loss: 0.28978264331817627, val metric: 0.6915867017663043
[15:02:46] Epoch: 1, train loss: 0.24367769062519073, val loss: 0.2738344967365265, val metric: 0.7211224099864131
[15:02:46] Epoch: 2, train loss: 0.21612469851970673, val loss: 0.2693524658679962, val metric: 0.7317690641983695
[15:02:46] Epoch: 3, train loss: 0.18013358116149902, val loss: 0.31211358308792114, val metric: 0.7004659901494565
[15:02:46] Epoch: 4, train loss: 0.16005361080169678, val loss: 0.31500178575515747, val metric: 0.7096371858016304
[15:02:46] Early stopping: val loss: 0.27935606241226196, val metric: 0.7314346976902173
[15:02:46] ===== Start working with fold 4 for Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 =====
[15:02:47] Epoch: 0, train loss: 0.2715047299861908, val loss: 0.27490749955177307, val metric: 0.672867484714674
[15:02:47] Epoch: 1, train loss: 0.24714724719524384, val loss: 0.2625226378440857, val metric: 0.7219928243885869
[15:02:47] Epoch: 2, train loss: 0.21466588973999023, val loss: 0.26622310280799866, val metric: 0.7148384425951086
[15:02:47] Epoch: 3, train loss: 0.18601463735103607, val loss: 0.28521138429641724, val metric: 0.6925048828124999
[15:02:47] Epoch: 4, train loss: 0.15070100128650665, val loss: 0.2958201467990875, val metric: 0.6602305536684783
[15:02:47] Early stopping: val loss: 0.2677777111530304, val metric: 0.7166058084239131
[15:02:47] Fitting Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 finished. score = 0.7086451902861568
[15:02:47] Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1 fitting and predicting completed
[15:02:47] Time left 2973.02 secs
[15:02:47] Layer 1 training completed.
[15:02:47] Blending: optimization starts with equal weights. Score = 0.7380476
[15:02:47] Blending: iteration 0: score = 0.7394669, weights = [0.45736045 0.0553336 0.487306 ]
[15:02:48] Blending: iteration 1: score = 0.7395753, weights = [0.4892029 0. 0.51079714]
[15:02:48] Blending: no improvements for score. Terminated.
[15:02:48] Blending: best score = 0.7395753, best weights = [0.4892029 0. 0.51079714]
[15:02:48] Automl preset training completed in 27.27 seconds
[15:02:48] Model description:
Final prediction for new objects (level 0) =
0.48920 * (5 averaged models Lvl_0_Pipe_0_Mod_0_LightGBM) +
0.51080 * (5 averaged models Lvl_0_Pipe_1_Mod_1_TorchNN_dense_1)
[26]:
array([[0.06395157],
[0.04285344],
[0.04808115],
...,
[0.04276791],
[0.19339147],
[0.10395089]], dtype=float32)