Tutorial 11: time series
![]()
There are some features how LightAutoML makes forecast for time-series tasks:
multi-output strategy for forecasting time series if horizon is more than 1 point (forecast simultaneously over the entire horizon)
global-modelling approach for handling multiple time series (one model for all time series in the dataset)
In this tutorial you will learn how to:
run LightAutoML training on data with one or many time series
configure time series features transformers’ parameters
Official LightAutoML github repository is here.
0. Prerequisites
0.0. install LightAutoML
[ ]:
# !pip install -U lightautoml
0.1. Import libraries
[2]:
# Standard python libraries
import os
# Installed libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
# Imports from our package
from lightautoml.tasks import Task
from lightautoml.addons.autots.base import AutoTS
from lightautoml.dataset.roles import DatetimeRole
from lightautoml.automl.base import AutoML
from lightautoml.ml_algo.boost_cb import BoostCB
from lightautoml.ml_algo.linear_sklearn import LinearLBFGS
from lightautoml.pipelines.features.lgb_pipeline import LGBSeqSimpleFeatures
from lightautoml.pipelines.features.linear_pipeline import LinearTrendFeatures
from lightautoml.pipelines.ml.base import MLPipeline
from lightautoml.reader.base import DictToPandasSeqReader
from lightautoml.automl.blend import WeightedBlender
from lightautoml.ml_algo.random_forest import RandomForestSklearn
# Disable warnings
import warnings
warnings.filterwarnings("ignore")
0.2. Constants and functions
Here we setup the constants to use in the kernel:
HORIZON- number of points to forecastTARGET_COLUMN- target column name in datasetDATE_COLUMN- date column name in datasetID_COLUMN- id column name in dataset
[3]:
HORIZON = 30
TARGET_COLUMN = "value"
DATE_COLUMN = "date"
ID_COLUMN = "ID"
[4]:
def draw_raw_ts(
data: pd.DataFrame,
id_column: str,
target_column: str,
date_column: str,
ncols: int = 2,
):
"""Draw graphs of time series with specified parameters.
Args:
- data: pd.DataFrame with time series data
- id_column: id column name in dataset
- target_column: target column name in dataset
- date_column: date column name in dataset
- ncols: number of columns for subplot's grid
"""
# Initialize grid's shape
num_ts = data[id_column].nunique()
nrows = num_ts // ncols + num_ts % ncols
fig, ax = plt.subplots(
nrows,
ncols,
figsize=(24, 5 * nrows)
)
axes_to_del = nrows * ncols - num_ts
for i in range(axes_to_del):
i_row = (nrows - 1) - i // ncols
i_col = (ncols - 1) - i % ncols
fig.delaxes(ax[i_row][i_col])
# Draw graphs
for i, ts_id in enumerate(data[id_column].unique()):
i_row = i // ncols
i_col = i % ncols
ts_df = data[data[id_column] == ts_id]
ax = ax.reshape(nrows, ncols)
ax[i_row, i_col].plot(ts_df[date_column], ts_df[target_column])
ax[i_row, i_col].title.set_text(f"TS with ID {ts_id}")
0.3. Data loading
[5]:
df = pd.read_csv('../data/ts_data.csv')
df[DATE_COLUMN] = pd.to_datetime(df[DATE_COLUMN])
display(df.head())
print(f"data shape: {df.shape}")
print(f"number of time series in data: {df[ID_COLUMN].nunique()}")
| date | value | ID | |
|---|---|---|---|
| 0 | 2020-01-01 | 2.100760 | 0 |
| 1 | 2020-01-02 | 2.106072 | 0 |
| 2 | 2020-01-03 | 2.291461 | 0 |
| 3 | 2020-01-04 | 2.322224 | 0 |
| 4 | 2020-01-05 | 2.140932 | 0 |
data shape: (10000, 3)
number of time series in data: 5
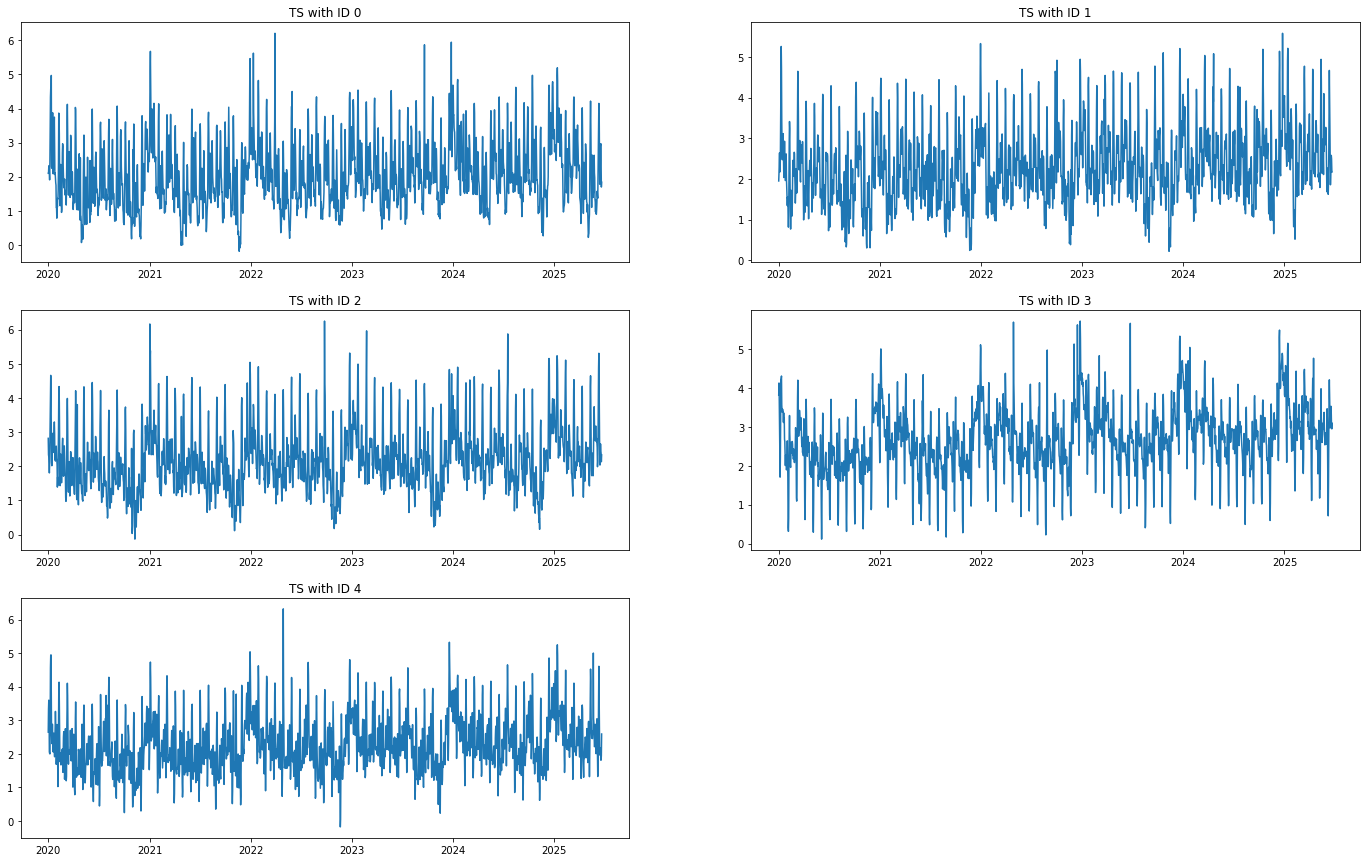
This data is simulated and presented time series, contained such components as trend, seasonality, events and future reg.
On the cell below we draw our time series:
[6]:
draw_raw_ts(df, ID_COLUMN, TARGET_COLUMN, DATE_COLUMN)
0.4. Data splitting for train-holdout
Let’s make forecast of 30 next points. So, we should make train-test-split for each times series in our data.
[7]:
# Assume, that our time series are aligned and have identical timestamps.
test_start = df[df[ID_COLUMN] == 0][DATE_COLUMN].values[-HORIZON]
train = df[df[DATE_COLUMN] < test_start].copy()
test = df[df[DATE_COLUMN] >= test_start].copy()
1. Task definition
1.1. Task type
On the cell below we create Task object - the class to setup what task LightAutoML model should solve with specific loss and metric if necessary (more info can be found here in our documentation). For time series forecasting it should set as “multi:reg”:
[8]:
task = Task("multi:reg", greater_is_better=False, metric="mae", loss="mae")
multi:reg isn`t supported in lgb
1.2. Feature roles setup
The only role you must setup is "target" role, everything else (date, categorical, etc.) is up to user.
But if we have several time series in data, it is recommended to setup "id" role to group our observations. Also we can define seasonal features through DatetimeRole. Valid are: y, m, d, wd, hour, min, sec, ms, ns.
[9]:
univariate_roles = {
"target": TARGET_COLUMN,
DatetimeRole(seasonality=('d', 'm', 'wd'), base_date=True): DATE_COLUMN,
}
global_modelling_roles = {
"target": TARGET_COLUMN,
DatetimeRole(seasonality=('d', 'm', 'wd'), base_date=True): DATE_COLUMN,
"id": ID_COLUMN
}
1.3. LightAutoML (AutoTS) model creation
In this part we are going to create LightAutoML model with AutoTS class.
The params we can setup:
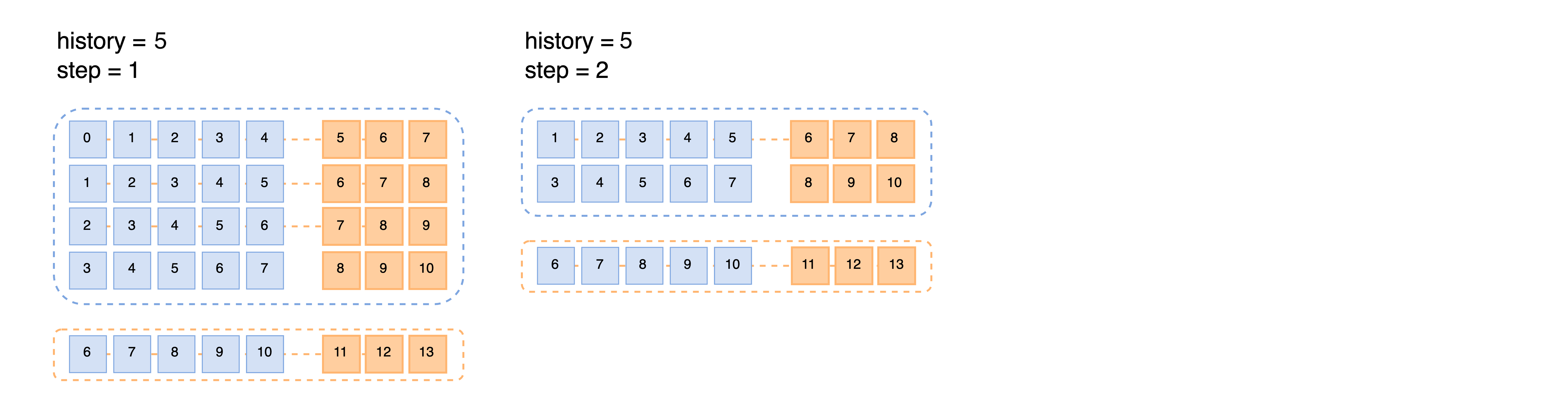
task- the type of the ML task (we defined it earlier)seq_params- parameter for Reader object, which works on the first step of data preparation:case- the type of problem we are solving (next_values: prediction of next values)n_target- forecasting horizonhistory- history size for feature generating (i.e., features for observation \(y_t\) are counted from observations (\(y_{t-history}\), …, \(y_{t-1}\)))step- in how many points to take the next observation in the training sample (the higher the step value –> the fewer observations fall into the training sample)test_last- technical parameter: test data are built by the last observation from the training samplefrom_last- technical parameter: build train features from last possible observation.
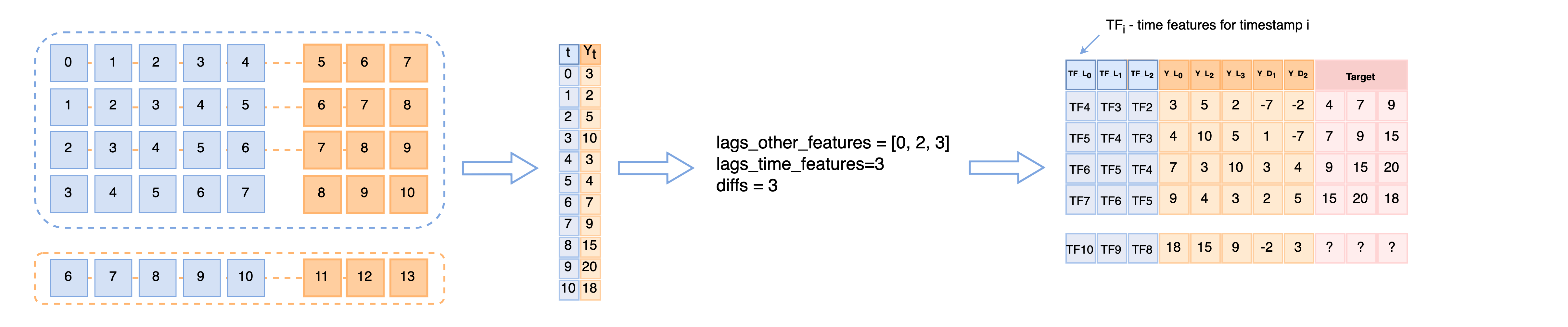
transformers_params- parameter for Transformer objects, which are needed to make features from raw time serieslag_features- bool/int/list/array: lags to make lag features for features other than datelag_time_features- bool/int/list/array: lags to make lag features for date featuresdiff_features- bool/int/list/array: lags to make difference features for features other than date
trend_params- parameter for TrendModel object, which is needed to detrend the time series before using the main AutoML class
Note: Parameters within the transformers_params may be configured as True/False, or integer, list, numpy-array:
True: use default values (lag_other_features=30, lag_time_features=30, diff_features=7)
int: use all lags and diffs up to the input number (range)
list: use certain lags and diffs specified in the list
There are some figures which can be helpful for better understanding these params:
Firstly, let’s generalise regression task of time series forecasting:
with known values for timestamps from \(T_{N+1}\) to \(T_0\) we should predict ones for timestamps \(T_{1}, ..., T_{F}\)

assume that \(N=10\) and \(F = 3\) and get train and test index arrays for values in time series:

Firstly, the graph below is about history and step parameters:
Now let’s take the first case and understand how transformers_params work and how train and test samples look like after transformations:
[10]:
seq_params = {
"seq0": {
"case": "next_values",
"params": {
"n_target": HORIZON,
"history": HORIZON,
"step": 1,
"from_last": True,
"test_last": True
}
}
}
transformers_params = {
"lag_features": 30,
"lag_time_features": 30,
"diff_features": [1, 2, 3, 4, 5, 6, 7, 14],
}
# You can try specify parameters for trend model too
# trend_params = {
# 'trend': False,
# 'train_on_trend': False,
# 'trend_type': 'decompose', # one of 'decompose', 'decompose_STL', 'linear' or 'rolling'
# 'trend_size': 1,
# 'decompose_period': 30,
# 'detect_step_quantile': 0.01,
# 'detect_step_window': 1,
# 'detect_step_threshold': 0.7,
# 'rolling_size': 1,
# 'verbose': 0
# }
automl = AutoTS(
task,
reader_params = {
"seq_params": seq_params
},
time_series_trend_params={
"trend": False,
},
time_series_pipeline_params=transformers_params
)
Important note: reader_params, time_series_trend_params, time_series_pipeline_params, general_params keys are the YAML config keys, which is used inside TabularAutoML preset. More details on its structure with explanation comments can be found inside the lightautoml/automl/presets/time_series_config.yaml file. Each key from this config can be modified with user settings during both to providing .yml file and modifying while AutoTS class initialization like in the cell
above.
2. AutoML training
2.1. Univariate LightAutoML
[11]:
# leave only ts with ID = 4
ID = 4
univariate_train = train[train[ID_COLUMN] == ID].drop("ID", axis=1)
univariate_test = test[test[ID_COLUMN] == ID].drop("ID", axis=1)
[12]:
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
[13]:
univariate_train_pred, _ = automl.fit_predict(univariate_train, univariate_roles, verbose=4)
univariate_forecast, _ = automl.predict(univariate_train)
[10:24:17] Stdout logging level is DEBUG.
[10:24:17] Task: multi:reg
[10:24:17] Start automl preset with listed constraints:
[10:24:17] - time: 3600.00 seconds
[10:24:17] - CPU: 4 cores
[10:24:17] - memory: 16 GB
[17:58:26] Layer 1 train process start. Time left 3599.96 secs
[17:58:26] Start fitting Lvl_0_Pipe_0_Mod_0_RFSklearn ...
[17:58:26] Training params: {'bootstrap': True, 'ccp_alpha': 0.0, 'max_depth': None, 'max_features': 'sqrt', 'max_leaf_nodes': None, 'max_samples': None, 'min_samples_leaf': 32, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'n_estimators': 500, 'n_jobs': 4, 'oob_score': False, 'random_state': 42, 'warm_start': False, 'verbose': 0, 'criterion': 'mse'}
[17:58:26] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_RFSklearn =====
[17:58:27] Score for RF model: -0.474507
[17:58:27] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_RFSklearn =====
[17:58:28] Score for RF model: -0.468268
[17:58:28] Fitting Lvl_0_Pipe_0_Mod_0_RFSklearn finished. score = -0.4713888963184421
[17:58:28] Lvl_0_Pipe_0_Mod_0_RFSklearn fitting and predicting completed
[17:58:28] Time left 3598.34 secs
[17:58:28] Start fitting Lvl_0_Pipe_1_Mod_0_LinearL2 ...
[17:58:28] Training params: {'tol': 1e-06, 'max_iter': 100, 'cs': [1e-05, 5e-05, 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 5, 10, 50, 100, 500, 1000, 5000, 10000, 50000, 100000], 'early_stopping': 2, 'categorical_idx': [], 'embed_sizes': (), 'data_size': 188}
[17:58:28] ===== Start working with fold 0 for Lvl_0_Pipe_1_Mod_0_LinearL2 =====
[17:58:28] Linear model: C = 1e-05 score = -0.6003076791232048
[17:58:28] Linear model: C = 5e-05 score = -0.5183533156110102
[17:58:29] Linear model: C = 0.0001 score = -0.46330821971023245
[17:58:29] Linear model: C = 0.0005 score = -0.36810350419844357
[17:58:29] Linear model: C = 0.001 score = -0.35480725252195533
[17:58:29] Linear model: C = 0.005 score = -0.3475977814992737
[17:58:29] Linear model: C = 0.01 score = -0.3480328256824163
[17:58:30] Linear model: C = 0.05 score = -0.3484652342803444
[17:58:30] ===== Start working with fold 1 for Lvl_0_Pipe_1_Mod_0_LinearL2 =====
[17:58:30] Linear model: C = 1e-05 score = -0.6028475283394467
[17:58:30] Linear model: C = 5e-05 score = -0.5207041477349572
[17:58:30] Linear model: C = 0.0001 score = -0.4659881593860412
[17:58:30] Linear model: C = 0.0005 score = -0.3684143016750015
[17:58:31] Linear model: C = 0.001 score = -0.3556188196228592
[17:58:31] Linear model: C = 0.005 score = -0.34978738837360196
[17:58:31] Linear model: C = 0.01 score = -0.3501108550228322
[17:58:31] Linear model: C = 0.05 score = -0.35125563103009994
[17:58:31] Fitting Lvl_0_Pipe_1_Mod_0_LinearL2 finished. score = -0.34869201204086625
[17:58:31] Lvl_0_Pipe_1_Mod_0_LinearL2 fitting and predicting completed
[17:58:31] Time left 3594.93 secs
[17:58:31] Start fitting Lvl_0_Pipe_2_Mod_0_CatBoost ...
[17:58:31] Training params: {'task_type': 'GPU', 'thread_count': 4, 'random_seed': 42, 'num_trees': 3000, 'learning_rate': 0.03, 'l2_leaf_reg': 0.01, 'bootstrap_type': 'Bernoulli', 'grow_policy': 'SymmetricTree', 'max_depth': 5, 'min_data_in_leaf': 1, 'one_hot_max_size': 10, 'fold_permutation_block': 1, 'boosting_type': 'Plain', 'boost_from_average': True, 'od_type': 'Iter', 'od_wait': 100, 'max_bin': 32, 'feature_border_type': 'GreedyLogSum', 'nan_mode': 'Min', 'verbose': 100, 'allow_writing_files': False, 'devices': '0'}
[17:58:31] ===== Start working with fold 0 for Lvl_0_Pipe_2_Mod_0_CatBoost =====
[17:58:32] 0: learn: 4.4726230 test: 4.4551552 best: 4.4551552 (0) total: 59.3ms remaining: 2m 57s
[17:58:33] 100: learn: 2.5849946 test: 2.8315490 best: 2.8315490 (100) total: 1.29s remaining: 36.9s
[17:58:34] 200: learn: 1.8855638 test: 2.2618428 best: 2.2618428 (200) total: 2.5s remaining: 34.7s
[17:58:35] 300: learn: 1.5189472 test: 1.9874703 best: 1.9874703 (300) total: 3.72s remaining: 33.3s
[17:58:36] 400: learn: 1.2936364 test: 1.8444599 best: 1.8444599 (400) total: 4.9s remaining: 31.8s
[17:58:38] 500: learn: 1.1450053 test: 1.7661319 best: 1.7661319 (500) total: 6.12s remaining: 30.5s
[17:58:39] 600: learn: 1.0355444 test: 1.7198144 best: 1.7198144 (600) total: 7.27s remaining: 29s
[17:58:40] 700: learn: 0.9461529 test: 1.6905038 best: 1.6905038 (700) total: 8.49s remaining: 27.8s
[17:58:41] 800: learn: 0.8698428 test: 1.6713547 best: 1.6713547 (800) total: 9.64s remaining: 26.5s
[17:58:42] 900: learn: 0.8034182 test: 1.6592994 best: 1.6592994 (900) total: 10.8s remaining: 25.2s
[17:58:44] 1000: learn: 0.7435150 test: 1.6494466 best: 1.6493530 (997) total: 12s remaining: 23.9s
[17:58:45] 1100: learn: 0.6882164 test: 1.6402117 best: 1.6402017 (1099) total: 13.2s remaining: 22.7s
[17:58:46] 1200: learn: 0.6392184 test: 1.6336748 best: 1.6336748 (1200) total: 14.4s remaining: 21.6s
[17:58:47] 1300: learn: 0.5943148 test: 1.6284005 best: 1.6283444 (1299) total: 15.7s remaining: 20.5s
[17:58:48] 1400: learn: 0.5537223 test: 1.6237273 best: 1.6237273 (1400) total: 16.9s remaining: 19.3s
[17:58:50] 1500: learn: 0.5174100 test: 1.6217630 best: 1.6217572 (1499) total: 18.1s remaining: 18s
[17:58:51] 1600: learn: 0.4829392 test: 1.6189425 best: 1.6189425 (1600) total: 19.3s remaining: 16.8s
[17:58:52] 1700: learn: 0.4513613 test: 1.6168994 best: 1.6168994 (1700) total: 20.4s remaining: 15.6s
[17:58:53] 1800: learn: 0.4221131 test: 1.6147198 best: 1.6147198 (1800) total: 21.6s remaining: 14.4s
[17:58:55] 1900: learn: 0.3947037 test: 1.6129983 best: 1.6129983 (1900) total: 22.9s remaining: 13.2s
[17:58:56] 2000: learn: 0.3704698 test: 1.6118408 best: 1.6118361 (1999) total: 24.1s remaining: 12s
[17:58:57] 2100: learn: 0.3473040 test: 1.6108620 best: 1.6108613 (2099) total: 25.2s remaining: 10.8s
[17:58:58] 2200: learn: 0.3258960 test: 1.6102695 best: 1.6102651 (2188) total: 26.4s remaining: 9.59s
[17:58:59] 2300: learn: 0.3054025 test: 1.6097875 best: 1.6097492 (2296) total: 27.6s remaining: 8.38s
[17:59:00] 2400: learn: 0.2867054 test: 1.6090802 best: 1.6090795 (2398) total: 28.8s remaining: 7.17s
[17:59:02] 2500: learn: 0.2689507 test: 1.6081654 best: 1.6081654 (2500) total: 29.9s remaining: 5.97s
[17:59:03] 2600: learn: 0.2525349 test: 1.6076868 best: 1.6076019 (2590) total: 31.1s remaining: 4.77s
[17:59:04] 2700: learn: 0.2377121 test: 1.6073861 best: 1.6073861 (2700) total: 32.3s remaining: 3.57s
[17:59:05] 2800: learn: 0.2229549 test: 1.6071654 best: 1.6071654 (2800) total: 33.4s remaining: 2.38s
[17:59:06] 2900: learn: 0.2094542 test: 1.6066872 best: 1.6066869 (2899) total: 34.6s remaining: 1.18s
[17:59:07] 2999: learn: 0.1970519 test: 1.6066699 best: 1.6066511 (2993) total: 35.8s remaining: 0us
[17:59:07] bestTest = 1.606651141
[17:59:07] bestIteration = 2993
[17:59:07] Shrink model to first 2994 iterations.
[17:59:08] ===== Start working with fold 1 for Lvl_0_Pipe_2_Mod_0_CatBoost =====
[17:59:08] 0: learn: 4.4577437 test: 4.4867925 best: 4.4867925 (0) total: 15.6ms remaining: 46.8s
[17:59:09] 100: learn: 2.6137326 test: 2.8394343 best: 2.8394343 (100) total: 1.19s remaining: 34.2s
[17:59:10] 200: learn: 1.8909167 test: 2.2558778 best: 2.2558778 (200) total: 2.38s remaining: 33.2s
[17:59:11] 300: learn: 1.4986037 test: 1.9673679 best: 1.9673679 (300) total: 3.58s remaining: 32.1s
[17:59:12] 400: learn: 1.2687985 test: 1.8194061 best: 1.8194061 (400) total: 4.75s remaining: 30.8s
[17:59:14] 500: learn: 1.1222801 test: 1.7438983 best: 1.7438983 (500) total: 6.06s remaining: 30.2s
[17:59:15] 600: learn: 1.0116269 test: 1.6987285 best: 1.6987285 (600) total: 7.25s remaining: 29s
[17:59:16] 700: learn: 0.9254741 test: 1.6695112 best: 1.6695112 (700) total: 8.44s remaining: 27.7s
[17:59:17] 800: learn: 0.8495263 test: 1.6502003 best: 1.6501991 (799) total: 9.64s remaining: 26.5s
[17:59:18] 900: learn: 0.7812408 test: 1.6338258 best: 1.6337881 (899) total: 10.8s remaining: 25.2s
[17:59:20] 1000: learn: 0.7249770 test: 1.6227465 best: 1.6227465 (1000) total: 12s remaining: 24s
[17:59:21] 1100: learn: 0.6742388 test: 1.6164241 best: 1.6164241 (1100) total: 13.2s remaining: 22.8s
[17:59:22] 1200: learn: 0.6261038 test: 1.6104160 best: 1.6103175 (1199) total: 14.4s remaining: 21.6s
[17:59:23] 1300: learn: 0.5812009 test: 1.6058196 best: 1.6058196 (1300) total: 15.6s remaining: 20.3s
[17:59:24] 1400: learn: 0.5414582 test: 1.6023364 best: 1.6023274 (1396) total: 16.8s remaining: 19.1s
[17:59:26] 1500: learn: 0.5047374 test: 1.5997954 best: 1.5997954 (1500) total: 17.9s remaining: 17.9s
[17:59:27] 1600: learn: 0.4710768 test: 1.5971879 best: 1.5971516 (1599) total: 19.1s remaining: 16.7s
[17:59:28] 1700: learn: 0.4406853 test: 1.5948181 best: 1.5948181 (1700) total: 20.3s remaining: 15.5s
[17:59:29] 1800: learn: 0.4122589 test: 1.5932432 best: 1.5932432 (1800) total: 21.5s remaining: 14.3s
[17:59:30] 1900: learn: 0.3856189 test: 1.5923377 best: 1.5922775 (1884) total: 22.7s remaining: 13.1s
[17:59:31] 2000: learn: 0.3613043 test: 1.5910058 best: 1.5910058 (2000) total: 23.8s remaining: 11.9s
[17:59:33] 2100: learn: 0.3383675 test: 1.5898274 best: 1.5898274 (2100) total: 25s remaining: 10.7s
[17:59:34] 2200: learn: 0.3172203 test: 1.5889919 best: 1.5889524 (2197) total: 26.2s remaining: 9.51s
[17:59:35] 2300: learn: 0.2974622 test: 1.5885660 best: 1.5885542 (2299) total: 27.4s remaining: 8.32s
[17:59:36] 2400: learn: 0.2794474 test: 1.5876316 best: 1.5876312 (2399) total: 28.6s remaining: 7.13s
[17:59:37] 2500: learn: 0.2620195 test: 1.5870893 best: 1.5870893 (2500) total: 29.8s remaining: 5.94s
[17:59:39] 2600: learn: 0.2461638 test: 1.5866054 best: 1.5865939 (2598) total: 30.9s remaining: 4.75s
[17:59:40] 2700: learn: 0.2310694 test: 1.5863323 best: 1.5863064 (2696) total: 32.1s remaining: 3.55s
[17:59:41] 2800: learn: 0.2173924 test: 1.5859899 best: 1.5859823 (2799) total: 33.3s remaining: 2.37s
[17:59:42] 2900: learn: 0.2046222 test: 1.5855330 best: 1.5855330 (2900) total: 34.5s remaining: 1.18s
[17:59:43] 2999: learn: 0.1924596 test: 1.5853173 best: 1.5852992 (2953) total: 35.6s remaining: 0us
[17:59:43] bestTest = 1.585299221
[17:59:43] bestIteration = 2953
[17:59:43] Shrink model to first 2954 iterations.
[17:59:43] Fitting Lvl_0_Pipe_2_Mod_0_CatBoost finished. score = -0.22094300934924996
[17:59:43] Lvl_0_Pipe_2_Mod_0_CatBoost fitting and predicting completed
[17:59:43] Time left 3522.77 secs
[17:59:43] Layer 1 training completed.
[17:59:43] Blending: optimization starts with equal weights and score -0.3009012970426841
[17:59:43] Blending: iteration 0: score = -0.22094300934924996, weights = [0. 0. 1.]
[17:59:43] Blending: iteration 1: score = -0.22094300934924996, weights = [0. 0. 1.]
[17:59:43] Blending: no score update. Terminated
[17:59:43] Automl preset training completed in 77.27 seconds
[10:25:54] Model description:
Final prediction for new objects (level 0) =
1.00000 * (2 averaged models Lvl_0_Pipe_2_Mod_0_CatBoost)
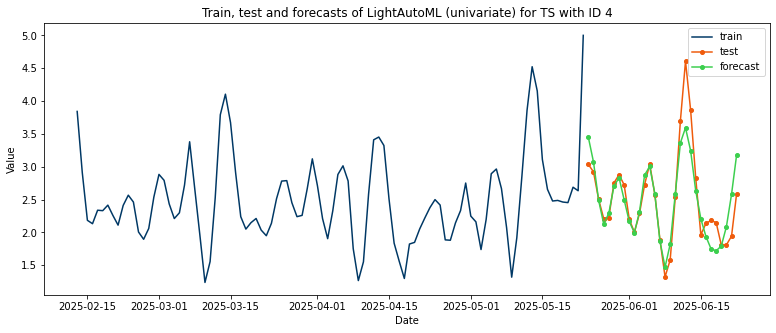
Let’s take a look on forecasts of univariate time series and check MAE
[14]:
print(univariate_forecast, "\n")
print(f"MAE: {mean_absolute_error(univariate_test.value, univariate_forecast)}")
[3.44697142 3.073035 2.49203897 2.1270709 2.29297566 2.70116901
2.83488226 2.49551201 2.16700649 1.99528813 2.31517577 2.87421489
3.00472379 2.59042096 1.8664093 1.47073889 1.81992817 2.58693051
3.36398268 3.59384632 3.24508047 2.63568759 2.20735097 1.9374007
1.74858916 1.72028816 1.79335809 2.08676887 2.57858872 3.18161464]
MAE: 0.22544950642226508
Get a graph of model’s predictions in comparison with true values
[15]:
last_N = min(len(train), 100)
fig = plt.figure(figsize=(13, 5))
plt.plot(
univariate_train[DATE_COLUMN][-last_N:],
univariate_train[TARGET_COLUMN][-last_N:],
c="#003865",
label="train"
)
plt.plot(
univariate_test[DATE_COLUMN],
univariate_test[TARGET_COLUMN],
c="#EF5B0C",
label="test",
marker="o",
markersize=4
)
plt.plot(
univariate_test[DATE_COLUMN],
univariate_forecast,
c="#3CCF4E",
label="forecast",
marker="o",
markersize=4
)
plt.xlabel("Date")
plt.ylabel("Value")
plt.title(f"Train, test and forecasts of LightAutoML (univariate) for TS with ID {ID}")
plt.legend()
plt.show()
One by one make forecasts for all time series in dataset and collect them to a new pd.DataFrame:
[16]:
ID_array = np.repeat(df[ID_COLUMN].unique(), HORIZON)
test_array = np.array([])
pred_array = np.array([])
date_array = np.array([]).astype("datetime64")
for ts_id in df[ID_COLUMN].unique():
univariate_train = train[train[ID_COLUMN] == ts_id]
univariate_test = test[test[ID_COLUMN] == ts_id]
# Model fit_predict
_, _ = automl.fit_predict(univariate_train, univariate_roles)
univariate_forecast, _ = automl.predict(univariate_train)
pred_array = np.append(pred_array, univariate_forecast)
test_array = np.append(test_array, univariate_test[TARGET_COLUMN].values)
date_array = np.append(date_array, univariate_test[DATE_COLUMN].values)
# Collect results
res_df_dict = {
"ID": ID_array,
"pred": pred_array,
"date": date_array,
"test": test_array
}
res_df_univariate = pd.DataFrame(res_df_dict)
[17]:
res_df_univariate.head()
[17]:
| ID | pred | date | test | |
|---|---|---|---|---|
| 0 | 0 | 2.427282 | 2025-05-24 | 1.581092 |
| 1 | 0 | 3.297728 | 2025-05-25 | 2.376163 |
| 2 | 0 | 3.508930 | 2025-05-26 | 2.627754 |
| 3 | 0 | 3.071776 | 2025-05-27 | 2.105468 |
| 4 | 0 | 2.333910 | 2025-05-28 | 1.969833 |
Check MAE for all time series:
[18]:
mae_df_univariate = res_df_univariate.groupby("ID").apply(
lambda x: mean_absolute_error(x["test"], x["pred"])
).reset_index()
mae_df_univariate.columns = ["ID", "MAE_univariate"]
mae_df_univariate
[18]:
| ID | MAE_univariate | |
|---|---|---|
| 0 | 0 | 0.371187 |
| 1 | 1 | 0.292606 |
| 2 | 2 | 0.435712 |
| 3 | 3 | 0.376864 |
| 4 | 4 | 0.225450 |
2.2. Global-modelling LightAutoML
[19]:
# Duplicate ID column for better feature generating
train["id_2"] = train[ID_COLUMN]
[20]:
oof_pred_seq = automl.fit_predict(train, roles=global_modelling_roles, verbose=4)
seq_test = automl.predict(train, return_raw=True)
[10:34:19] Stdout logging level is DEBUG.
[10:34:19] Task: multi:reg
[10:34:19] Start automl preset with listed constraints:
[10:34:19] - time: 3600.00 seconds
[10:34:19] - CPU: 4 cores
[10:34:19] - memory: 16 GB
[18:05:37] Layer 1 train process start. Time left 3599.91 secs
[18:05:38] Start fitting Lvl_0_Pipe_0_Mod_0_RFSklearn ...
[18:05:38] Training params: {'bootstrap': True, 'ccp_alpha': 0.0, 'max_depth': None, 'max_features': 'sqrt', 'max_leaf_nodes': None, 'max_samples': None, 'min_samples_leaf': 32, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'n_estimators': 500, 'n_jobs': 4, 'oob_score': False, 'random_state': 42, 'warm_start': False, 'verbose': 0, 'criterion': 'mse'}
[18:05:38] ===== Start working with fold 0 for Lvl_0_Pipe_0_Mod_0_RFSklearn =====
[18:05:40] Score for RF model: -0.478922
[18:05:40] ===== Start working with fold 1 for Lvl_0_Pipe_0_Mod_0_RFSklearn =====
[18:05:43] Score for RF model: -0.477559
[18:05:43] Fitting Lvl_0_Pipe_0_Mod_0_RFSklearn finished. score = -0.47824063661560884
[18:05:43] Lvl_0_Pipe_0_Mod_0_RFSklearn fitting and predicting completed
[18:05:43] Time left 3593.91 secs
[18:05:44] Start fitting Lvl_0_Pipe_1_Mod_0_LinearL2 ...
[18:05:44] Training params: {'tol': 1e-06, 'max_iter': 100, 'cs': [1e-05, 5e-05, 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 5, 10, 50, 100, 500, 1000, 5000, 10000, 50000, 100000], 'early_stopping': 2, 'categorical_idx': [], 'embed_sizes': (), 'data_size': 226}
[18:05:44] ===== Start working with fold 0 for Lvl_0_Pipe_1_Mod_0_LinearL2 =====
[18:05:44] Linear model: C = 1e-05 score = -0.5964374876210202
[18:05:44] Linear model: C = 5e-05 score = -0.4531700575784085
[18:05:44] Linear model: C = 0.0001 score = -0.4146961763297737
[18:05:45] Linear model: C = 0.0005 score = -0.38449422448982795
[18:05:45] Linear model: C = 0.001 score = -0.38138838560544014
[18:05:45] Linear model: C = 0.005 score = -0.38019812717729135
[18:05:45] Linear model: C = 0.01 score = -0.38034723995869585
[18:05:45] Linear model: C = 0.05 score = -0.38041431355765454
[18:05:45] ===== Start working with fold 1 for Lvl_0_Pipe_1_Mod_0_LinearL2 =====
[18:05:46] Linear model: C = 1e-05 score = -0.5906956397709
[18:05:46] Linear model: C = 5e-05 score = -0.45173117819934433
[18:05:46] Linear model: C = 0.0001 score = -0.4145036642322005
[18:05:46] Linear model: C = 0.0005 score = -0.3849509035123634
[18:05:47] Linear model: C = 0.001 score = -0.3813145757461596
[18:05:47] Linear model: C = 0.005 score = -0.37985413506750626
[18:05:47] Linear model: C = 0.01 score = -0.37999213463071496
[18:05:47] Linear model: C = 0.05 score = -0.38003681603029926
[18:05:47] Fitting Lvl_0_Pipe_1_Mod_0_LinearL2 finished. score = -0.3800261491230324
[18:05:47] Lvl_0_Pipe_1_Mod_0_LinearL2 fitting and predicting completed
[18:05:47] Time left 3589.22 secs
[18:05:48] Start fitting Lvl_0_Pipe_2_Mod_0_CatBoost ...
[18:05:48] Training params: {'task_type': 'GPU', 'thread_count': 4, 'random_seed': 42, 'num_trees': 3000, 'learning_rate': 0.03, 'l2_leaf_reg': 0.01, 'bootstrap_type': 'Bernoulli', 'grow_policy': 'SymmetricTree', 'max_depth': 5, 'min_data_in_leaf': 1, 'one_hot_max_size': 10, 'fold_permutation_block': 1, 'boosting_type': 'Plain', 'boost_from_average': True, 'od_type': 'Iter', 'od_wait': 100, 'max_bin': 32, 'feature_border_type': 'GreedyLogSum', 'nan_mode': 'Min', 'verbose': 100, 'allow_writing_files': False, 'devices': '0'}
[18:05:49] ===== Start working with fold 0 for Lvl_0_Pipe_2_Mod_0_CatBoost =====
[18:05:49] 0: learn: 4.9703982 test: 4.9996176 best: 4.9996176 (0) total: 43.1ms remaining: 2m 9s
[18:05:53] 100: learn: 3.1817923 test: 3.2535349 best: 3.2535349 (100) total: 4.01s remaining: 1m 55s
[18:05:57] 200: learn: 2.5726766 test: 2.6805614 best: 2.6805614 (200) total: 8.03s remaining: 1m 51s
[18:06:01] 300: learn: 2.2560121 test: 2.3947249 best: 2.3947249 (300) total: 12.1s remaining: 1m 48s
[18:06:05] 400: learn: 2.0597074 test: 2.2313428 best: 2.2313428 (400) total: 16.2s remaining: 1m 45s
[18:06:09] 500: learn: 1.9274641 test: 2.1288114 best: 2.1288114 (500) total: 20.4s remaining: 1m 41s
[18:06:13] 600: learn: 1.8216448 test: 2.0494447 best: 2.0494447 (600) total: 24.6s remaining: 1m 38s
[18:06:17] 700: learn: 1.7391222 test: 1.9927232 best: 1.9927232 (700) total: 28.7s remaining: 1m 34s
[18:06:22] 800: learn: 1.6764093 test: 1.9538165 best: 1.9538165 (800) total: 32.9s remaining: 1m 30s
[18:06:26] 900: learn: 1.6219885 test: 1.9225213 best: 1.9225213 (900) total: 37.1s remaining: 1m 26s
[18:06:30] 1000: learn: 1.5738942 test: 1.8971965 best: 1.8971965 (1000) total: 41.2s remaining: 1m 22s
[18:06:34] 1100: learn: 1.5308305 test: 1.8747704 best: 1.8747704 (1100) total: 45.4s remaining: 1m 18s
[18:06:38] 1200: learn: 1.4944545 test: 1.8602100 best: 1.8602100 (1200) total: 49.5s remaining: 1m 14s
[18:06:42] 1300: learn: 1.4584951 test: 1.8450711 best: 1.8450711 (1300) total: 53.6s remaining: 1m 10s
[18:06:46] 1400: learn: 1.4277984 test: 1.8356888 best: 1.8356888 (1400) total: 57.7s remaining: 1m 5s
[18:06:50] 1500: learn: 1.3976121 test: 1.8263948 best: 1.8263948 (1500) total: 1m 1s remaining: 1m 1s
[18:06:55] 1600: learn: 1.3703607 test: 1.8202220 best: 1.8202220 (1600) total: 1m 5s remaining: 57.6s
[18:06:59] 1700: learn: 1.3433452 test: 1.8133380 best: 1.8133380 (1700) total: 1m 10s remaining: 53.5s
[18:07:03] 1800: learn: 1.3172573 test: 1.8065216 best: 1.8065216 (1800) total: 1m 14s remaining: 49.3s
[18:07:07] 1900: learn: 1.2922313 test: 1.8003041 best: 1.8003041 (1900) total: 1m 18s remaining: 45.2s
[18:07:11] 2000: learn: 1.2687614 test: 1.7968015 best: 1.7968015 (2000) total: 1m 22s remaining: 41.1s
[18:07:15] 2100: learn: 1.2466742 test: 1.7934962 best: 1.7934962 (2100) total: 1m 26s remaining: 36.9s
[18:07:19] 2200: learn: 1.2247532 test: 1.7906494 best: 1.7906494 (2200) total: 1m 30s remaining: 32.8s
[18:07:23] 2300: learn: 1.2037321 test: 1.7880290 best: 1.7880053 (2299) total: 1m 34s remaining: 28.7s
[18:07:27] 2400: learn: 1.1833635 test: 1.7857023 best: 1.7857023 (2400) total: 1m 38s remaining: 24.6s
[18:07:31] 2500: learn: 1.1636590 test: 1.7833589 best: 1.7833589 (2500) total: 1m 42s remaining: 20.5s
[18:07:35] 2600: learn: 1.1448807 test: 1.7812717 best: 1.7812717 (2600) total: 1m 46s remaining: 16.3s
[18:07:39] 2700: learn: 1.1258719 test: 1.7781959 best: 1.7781959 (2700) total: 1m 50s remaining: 12.2s
[18:07:43] 2800: learn: 1.1079550 test: 1.7766084 best: 1.7766084 (2800) total: 1m 54s remaining: 8.14s
[18:07:47] 2900: learn: 1.0903868 test: 1.7753964 best: 1.7753941 (2899) total: 1m 58s remaining: 4.05s
[18:07:51] 2999: learn: 1.0737443 test: 1.7740101 best: 1.7740101 (2999) total: 2m 2s remaining: 0us
[18:07:51] bestTest = 1.774010135
[18:07:51] bestIteration = 2999
[18:07:51] ===== Start working with fold 1 for Lvl_0_Pipe_2_Mod_0_CatBoost =====
[18:07:52] 0: learn: 4.9945826 test: 4.9698499 best: 4.9698499 (0) total: 41.8ms remaining: 2m 5s
[18:07:56] 100: learn: 3.1884268 test: 3.2469980 best: 3.2469980 (100) total: 3.98s remaining: 1m 54s
[18:08:00] 200: learn: 2.5842575 test: 2.6880010 best: 2.6880010 (200) total: 7.96s remaining: 1m 50s
[18:08:04] 300: learn: 2.2647479 test: 2.4010427 best: 2.4010427 (300) total: 12s remaining: 1m 47s
[18:08:08] 400: learn: 2.0722203 test: 2.2444863 best: 2.2444863 (400) total: 16.1s remaining: 1m 44s
[18:08:12] 500: learn: 1.9358628 test: 2.1373584 best: 2.1373584 (500) total: 20.3s remaining: 1m 41s
[18:08:16] 600: learn: 1.8365382 test: 2.0652895 best: 2.0652895 (600) total: 24.4s remaining: 1m 37s
[18:08:20] 700: learn: 1.7542585 test: 2.0068865 best: 2.0068865 (700) total: 28.6s remaining: 1m 33s
[18:08:24] 800: learn: 1.6883776 test: 1.9628955 best: 1.9628955 (800) total: 32.7s remaining: 1m 29s
[18:08:29] 900: learn: 1.6305606 test: 1.9266863 best: 1.9266863 (900) total: 36.9s remaining: 1m 25s
[18:08:33] 1000: learn: 1.5848000 test: 1.9039980 best: 1.9039980 (1000) total: 41s remaining: 1m 21s
[18:08:37] 1100: learn: 1.5422530 test: 1.8820810 best: 1.8820810 (1100) total: 45.2s remaining: 1m 17s
[18:08:41] 1200: learn: 1.5048244 test: 1.8662495 best: 1.8662495 (1200) total: 49.3s remaining: 1m 13s
[18:08:45] 1300: learn: 1.4705212 test: 1.8536784 best: 1.8536784 (1300) total: 53.4s remaining: 1m 9s
[18:08:49] 1400: learn: 1.4377168 test: 1.8420271 best: 1.8420271 (1400) total: 57.5s remaining: 1m 5s
[18:08:53] 1500: learn: 1.4068988 test: 1.8320774 best: 1.8320661 (1499) total: 1m 1s remaining: 1m 1s
[18:08:57] 1600: learn: 1.3788303 test: 1.8235099 best: 1.8235099 (1600) total: 1m 5s remaining: 57.4s
[18:09:01] 1700: learn: 1.3520362 test: 1.8165897 best: 1.8165897 (1700) total: 1m 9s remaining: 53.3s
[18:09:06] 1800: learn: 1.3263396 test: 1.8109005 best: 1.8109005 (1800) total: 1m 13s remaining: 49.2s
[18:09:10] 1900: learn: 1.3017944 test: 1.8052676 best: 1.8052676 (1900) total: 1m 18s remaining: 45.1s
[18:09:14] 2000: learn: 1.2771414 test: 1.7995645 best: 1.7995645 (2000) total: 1m 22s remaining: 41s
[18:09:18] 2100: learn: 1.2540940 test: 1.7948637 best: 1.7948637 (2100) total: 1m 26s remaining: 36.9s
[18:09:22] 2200: learn: 1.2319167 test: 1.7913644 best: 1.7913580 (2194) total: 1m 30s remaining: 32.7s
[18:09:26] 2300: learn: 1.2107906 test: 1.7883785 best: 1.7883785 (2300) total: 1m 34s remaining: 28.6s
[18:09:30] 2400: learn: 1.1906539 test: 1.7857203 best: 1.7857203 (2400) total: 1m 38s remaining: 24.5s
[18:09:34] 2500: learn: 1.1705045 test: 1.7827000 best: 1.7827000 (2500) total: 1m 42s remaining: 20.4s
[18:09:38] 2600: learn: 1.1510307 test: 1.7808157 best: 1.7808028 (2598) total: 1m 46s remaining: 16.3s
[18:09:42] 2700: learn: 1.1323293 test: 1.7789892 best: 1.7789676 (2697) total: 1m 50s remaining: 12.2s
[18:09:46] 2800: learn: 1.1142749 test: 1.7767626 best: 1.7767626 (2800) total: 1m 54s remaining: 8.14s
[18:09:50] 2900: learn: 1.0964777 test: 1.7755168 best: 1.7755025 (2899) total: 1m 58s remaining: 4.05s
[18:09:54] 2999: learn: 1.0793822 test: 1.7741527 best: 1.7741169 (2997) total: 2m 2s remaining: 0us
[18:09:54] bestTest = 1.774116879
[18:09:54] bestIteration = 2997
[18:09:54] Shrink model to first 2998 iterations.
[18:09:54] Fitting Lvl_0_Pipe_2_Mod_0_CatBoost finished. score = -0.24088612521804945
[18:09:54] Lvl_0_Pipe_2_Mod_0_CatBoost fitting and predicting completed
[18:09:54] Time left 3342.18 secs
[18:09:54] Layer 1 training completed.
[18:09:54] Blending: optimization starts with equal weights and score -0.31863480146881884
[18:09:54] Blending: iteration 0: score = -0.24088612521804945, weights = [0. 0. 1.]
[18:09:55] Blending: iteration 1: score = -0.24088612521804945, weights = [0. 0. 1.]
[18:09:55] Blending: no score update. Terminated
[18:09:55] Automl preset training completed in 257.95 seconds
[10:40:24] Model description:
Final prediction for new objects (level 0) =
1.00000 * (2 averaged models Lvl_0_Pipe_2_Mod_0_CatBoost)
seq_test соis consisted of:
seq_test.date — base date, from which predictions are made
seq_test.id — id of time series
seq_test.data — predictions themselves
We can collect these values to the df.DataFrame:
[21]:
freq = pd.infer_freq(train[DATE_COLUMN].iloc[:10])
date_list = [seq_test.date[0] + pd.Timedelta(1+i, unit=freq) for i in range(HORIZON)]
date_list = date_list * len(seq_test.id)
pred_list = list(seq_test.data.reshape(-1))
id_list = np.repeat(seq_test.id, HORIZON)
df_dict = {
"ID": id_list,
"date": date_list,
"pred": pred_list
}
res_df_global = pd.DataFrame(df_dict)
res_df_global = res_df_global.merge(test, on=["ID", "date"])
res_df_global
[21]:
| ID | date | pred | value | |
|---|---|---|---|---|
| 0 | 0 | 2025-05-24 | 2.384080 | 1.581092 |
| 1 | 0 | 2025-05-25 | 3.279628 | 2.376163 |
| 2 | 0 | 2025-05-26 | 3.530711 | 2.627754 |
| 3 | 0 | 2025-05-27 | 3.079974 | 2.105468 |
| 4 | 0 | 2025-05-28 | 2.362342 | 1.969833 |
| ... | ... | ... | ... | ... |
| 145 | 4 | 2025-06-18 | 1.874377 | 2.149213 |
| 146 | 4 | 2025-06-19 | 1.947542 | 1.807998 |
| 147 | 4 | 2025-06-20 | 2.211135 | 1.810103 |
| 148 | 4 | 2025-06-21 | 2.608910 | 1.941590 |
| 149 | 4 | 2025-06-22 | 3.128166 | 2.590021 |
150 rows × 4 columns
Check MAE for all time series:
[22]:
mae_df_global = res_df_global.groupby("ID").apply(
lambda x: mean_absolute_error(x["value"], x["pred"])
).reset_index()
mae_df_global.columns = ["ID", "MAE_global"]
mae_df_global
[22]:
| ID | MAE_global | |
|---|---|---|
| 0 | 0 | 0.344390 |
| 1 | 1 | 0.227540 |
| 2 | 2 | 0.477782 |
| 3 | 3 | 0.342722 |
| 4 | 4 | 0.193969 |
Compare MAE for two strategies (univariate/local- and global-modelling):
[23]:
mae_df_global.merge(mae_df_univariate, on=["ID"])
[23]:
| ID | MAE_global | MAE_univariate | |
|---|---|---|---|
| 0 | 0 | 0.344390 | 0.371187 |
| 1 | 1 | 0.227540 | 0.292606 |
| 2 | 2 | 0.477782 | 0.435712 |
| 3 | 3 | 0.342722 | 0.376864 |
| 4 | 4 | 0.193969 | 0.225450 |
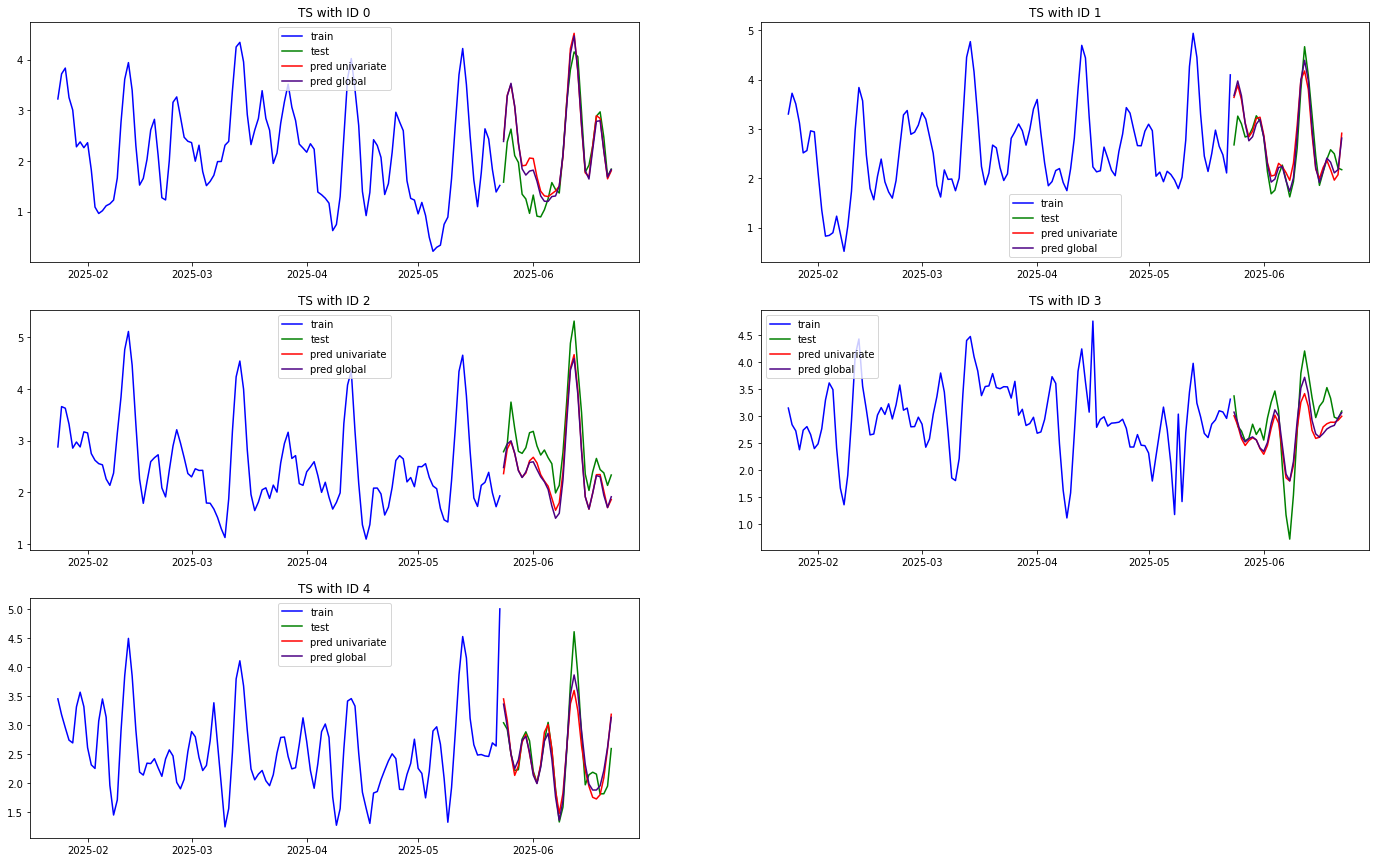
Lastly, get a graph of models’ predictions in comparison with each other and the true values
[24]:
LAST_TRAIN_N = 120
num_ids = len(df[ID_COLUMN].value_counts())
subplots_num_columns = 2
subplots_num_rows = num_ids // 2 + num_ids % 2
fig, ax = plt.subplots(
subplots_num_rows,
subplots_num_columns,
figsize=(24, 5 * subplots_num_rows)
)
for i, ts_id in enumerate(df[ID_COLUMN].unique()):
i_row = i // 2
i_col = i % 2
current_train = train[train[ID_COLUMN] == ts_id]
current_res_df_univariate = res_df_univariate[res_df_univariate[ID_COLUMN] == ts_id]
current_res_df_global = res_df_global[res_df_global[ID_COLUMN] == ts_id]
ax[i_row, i_col].plot(current_train[DATE_COLUMN][-LAST_TRAIN_N:], current_train[TARGET_COLUMN][-LAST_TRAIN_N:], c='b', label='train')
ax[i_row, i_col].plot(current_res_df_univariate[DATE_COLUMN], current_res_df_univariate["test"], c='g', label='test')
ax[i_row, i_col].plot(current_res_df_univariate[DATE_COLUMN], current_res_df_univariate["pred"], c='r', label='pred univariate')
ax[i_row, i_col].plot(current_res_df_global[DATE_COLUMN], current_res_df_global["pred"], c='indigo', label='pred global')
ax[i_row, i_col].title.set_text(f"TS with ID {ts_id}")
ax[i_row, i_col].legend()
axes_to_del = i_row * subplots_num_rows + i_col * subplots_num_columns - num_ids
for i in range(axes_to_del):
i_row = (subplots_num_rows - 1) - i // 2
i_col = (subplots_num_columns - 1) - i % 2
fig.delaxes(ax[i_row][i_col])
plt.show();