Tutorial 2: AutoWoE (WhiteBox model for binary classification on tabular data)
![]()
Official LightAutoML github repository is here
Scorecard
Linear model
Discretization
Selection and One-dimensional analysis
Whitebox pipeline:
General parameters
Technical
n_jobs
debug
Simple features typing and initial cleaning
1.1. Remove trash features
Medium: - th_nan - th_const1.2. Typling (auto or user defined)
Critical: - features_type (dict) {'age': 'real', 'education': 'cat', 'birth_date': (None, ("d", "wd"), ...}1.3. Categories and datetimes encoding
Critical: - features_type (for datetimes) Optional: - cat_alpha (int) - greater means more conservative encodingPre selection (based on BlackBox model importances)
Critical:
select_type (None or int)
imp_type (if type(select_type) is int ‘perm_imt’/’feature_imp’)
Optional:
imt_th (float) - threshold for select_type is None
Binning (discretization)
Critical:
monotonic / features_monotone_constraints
max_bin_count / max_bin_count
min_bin_size
cat_merge_to
nan_merge_to
Medium:
force_single_split
Optional:
min_bin_mults
min_gains_to_split
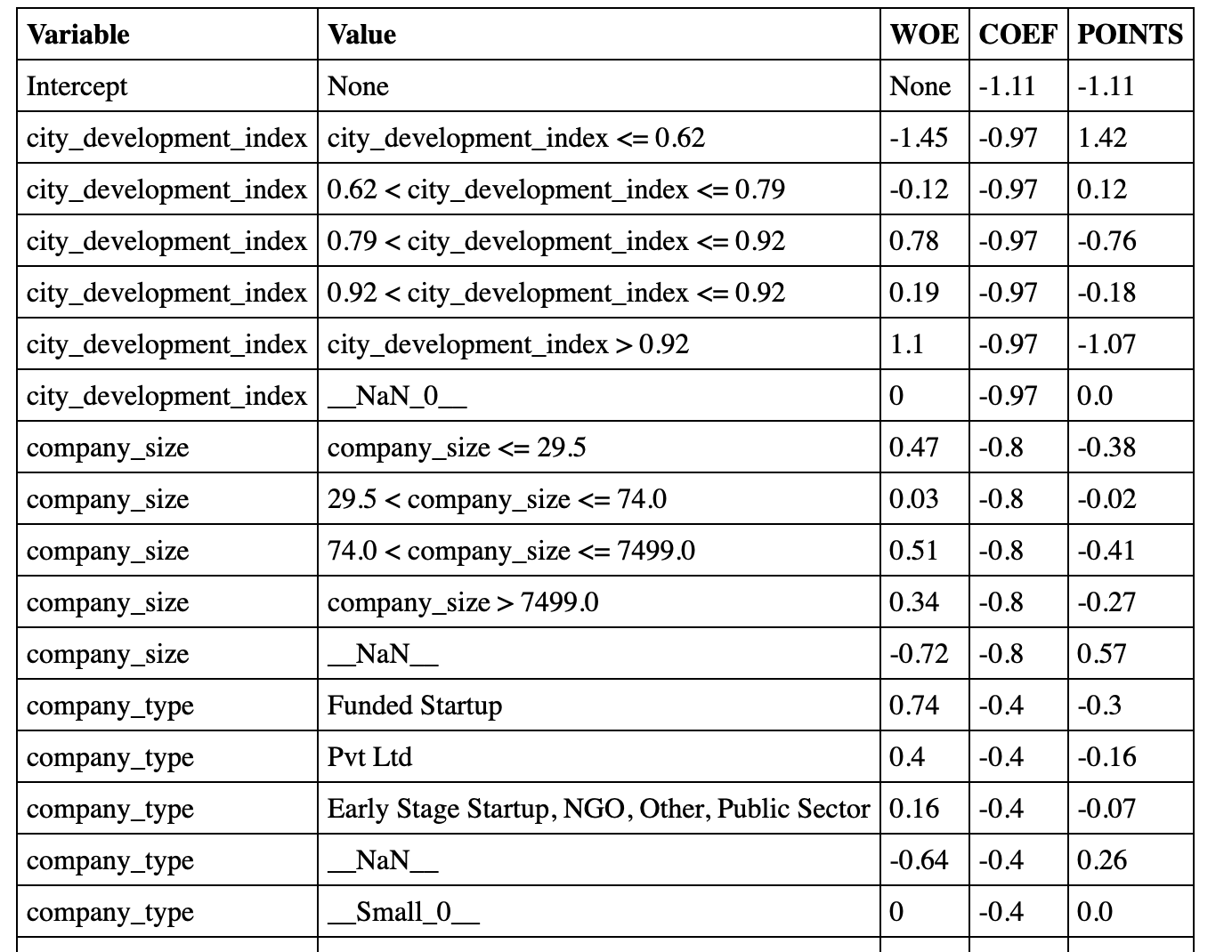
WoE estimation WoE = LN( ((% 0 in bin) / (% 0 in sample)) / ((% 1 in bin) / (% 1 in sample)) ):
Critical:
oof_woe
Optional:
woe_diff_th
n_folds (if oof_woe)
2nd selection stage:
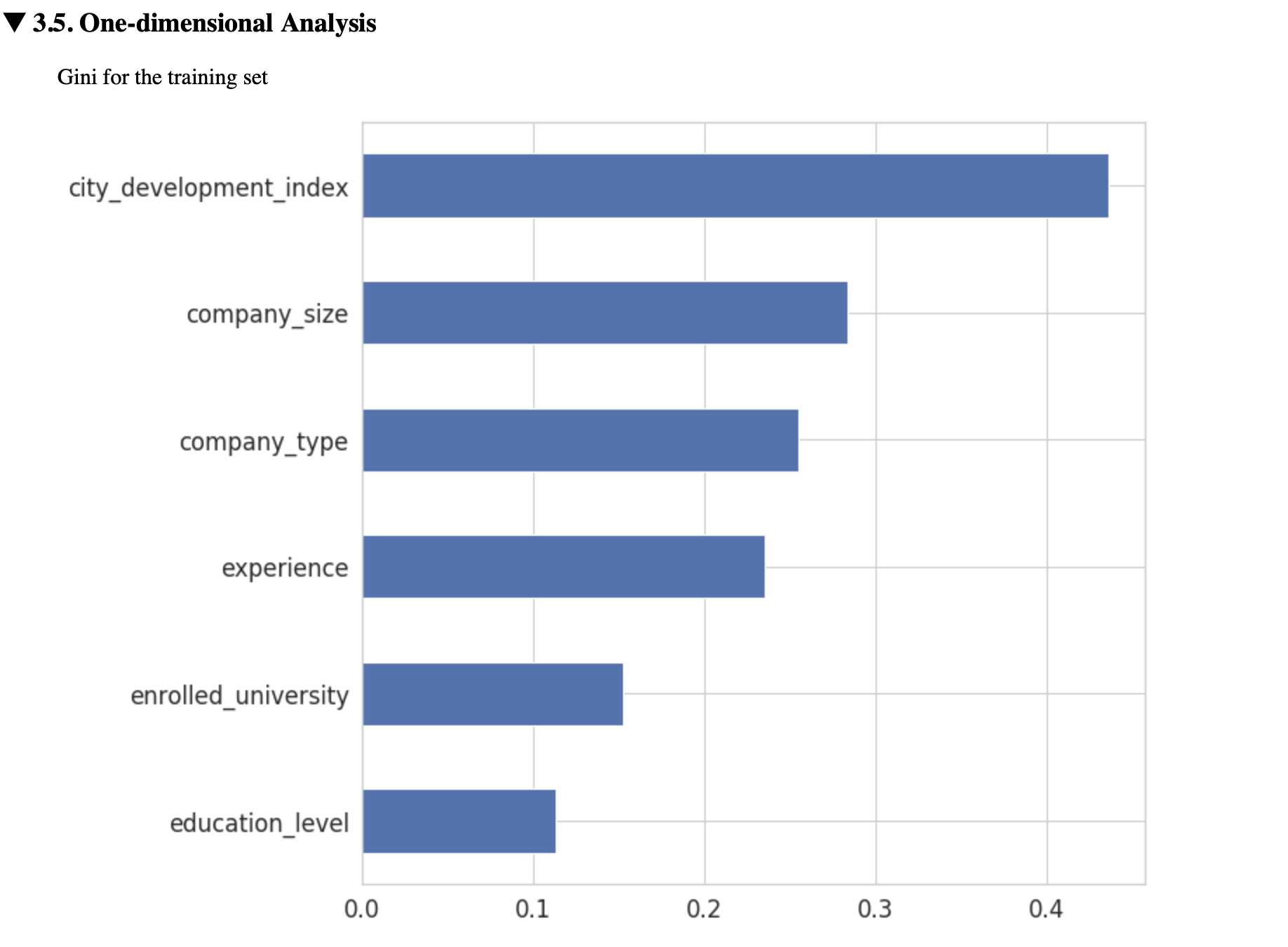
5.1. One-dimentional importance
Critical: - auc_th5.2. VIF
Critical: - vif_th5.3. Partial correlations
Critical: - pearson_th3rd selection stage (model based)
Optional:
n_folds
l1_base_step
l1_exp_step
Do not touch:
population_size
feature_groups_count
Fitting the final model
Critical:
regularized_refit
p_val (if not regularized_refit)
validation (if not regularized_refit)
Optional:
interpreted_model
l1_base_step (if regularized_refit)
l1_exp_step (if regularized_refit)
Report generation
report_params
Imports
[1]:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import os
import requests
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from autowoe import AutoWoE, ReportDeco
Reading the data and train/test split
[2]:
DATASET_DIR = '../data/'
DATASET_NAME = 'jobs_train.csv'
DATASET_FULLNAME = os.path.join(DATASET_DIR, DATASET_NAME)
DATASET_URL = 'https://raw.githubusercontent.com/AILab-MLTools/LightAutoML/master/examples/data/jobs_train.csv'
[3]:
%%time
if not os.path.exists(DATASET_FULLNAME):
os.makedirs(DATASET_DIR, exist_ok=True)
dataset = requests.get(DATASET_URL).text
with open(DATASET_FULLNAME, 'w') as output:
output.write(dataset)
CPU times: user 13 μs, sys: 6 μs, total: 19 μs
Wall time: 22.2 μs
[4]:
data = pd.read_csv(DATASET_FULLNAME)
[5]:
data
[5]:
| enrollee_id | city | city_development_index | gender | relevant_experience | enrolled_university | education_level | major_discipline | experience | company_size | company_type | last_new_job | training_hours | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 8949 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 21.0 | NaN | NaN | 1.0 | 36 | 1.0 |
| 1 | 29725 | city_40 | 0.776 | Male | No relevant experience | no_enrollment | Graduate | STEM | 15.0 | 99.0 | Pvt Ltd | 5.0 | 47 | 0.0 |
| 2 | 11561 | city_21 | 0.624 | NaN | No relevant experience | Full time course | Graduate | STEM | 5.0 | NaN | NaN | 0.0 | 83 | 0.0 |
| 3 | 33241 | city_115 | 0.789 | NaN | No relevant experience | NaN | Graduate | Business Degree | 0.0 | NaN | Pvt Ltd | 0.0 | 52 | 1.0 |
| 4 | 666 | city_162 | 0.767 | Male | Has relevant experience | no_enrollment | Masters | STEM | 21.0 | 99.0 | Funded Startup | 4.0 | 8 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 19153 | 7386 | city_173 | 0.878 | Male | No relevant experience | no_enrollment | Graduate | Humanities | 14.0 | NaN | NaN | 1.0 | 42 | 1.0 |
| 19154 | 31398 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 14.0 | NaN | NaN | 4.0 | 52 | 1.0 |
| 19155 | 24576 | city_103 | 0.920 | Male | Has relevant experience | no_enrollment | Graduate | STEM | 21.0 | 99.0 | Pvt Ltd | 4.0 | 44 | 0.0 |
| 19156 | 5756 | city_65 | 0.802 | Male | Has relevant experience | no_enrollment | High School | NaN | 0.0 | 999.0 | Pvt Ltd | 2.0 | 97 | 0.0 |
| 19157 | 23834 | city_67 | 0.855 | NaN | No relevant experience | no_enrollment | Primary School | NaN | 2.0 | NaN | NaN | 1.0 | 127 | 0.0 |
19158 rows × 14 columns
[6]:
train, test = train_test_split(data.drop('enrollee_id', axis=1), test_size=0.2, stratify=data['target'])
AutoWoe: default settings
[7]:
auto_woe_0 = AutoWoE(interpreted_model=True,
monotonic=False,
max_bin_count=5,
select_type=None,
pearson_th=0.9,
metric_th=.505,
vif_th=10.,
imp_th=0,
th_const=32,
force_single_split=True,
th_nan=0.01,
th_cat=0.005,
metric_tol=1e-4,
cat_alpha=100,
cat_merge_to="to_woe_0",
nan_merge_to="to_woe_0",
imp_type="feature_imp",
regularized_refit=False,
p_val=0.05,
verbose=2
)
auto_woe_0 = ReportDeco(auto_woe_0, )
[8]:
auto_woe_0.fit(train,
target_name="target",
)
[LightGBM] [Info] Number of positive: 3033, number of negative: 9227
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000495 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 518
[LightGBM] [Info] Number of data points in the train set: 12260, number of used features: 12
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.247390 -> initscore=-1.112582
[LightGBM] [Info] Start training from score -1.112582
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[11] val_test's auc: 0.810634
city processing...
city_development_index processing...
gender processing...
relevant_experience processing...
enrolled_university processing...
education_level processing...
major_discipline processing...
experience processing...
company_size processing...
company_type processing...
last_new_job processing...
training_hours processing...
dict_keys(['city', 'city_development_index', 'gender', 'relevant_experience', 'enrolled_university', 'education_level', 'major_discipline', 'experience', 'company_size', 'company_type', 'last_new_job', 'training_hours']) to selector !!!!!
Feature selection...
city_development_index -0.956279
company_size -0.859531
company_type -0.412534
experience -0.289671
enrolled_university -0.259906
education_level -0.603299
major_discipline -1.683294
dtype: float64
[9]:
test_prediction = auto_woe_0.predict_proba(test)
test_prediction
[9]:
array([0.05961808, 0.59490484, 0.02947085, ..., 0.14355782, 0.06430498,
0.0480986 ])
[10]:
roc_auc_score(test['target'].values, test_prediction)
[10]:
0.8016469307943301
[11]:
report_params = {"output_path": "HR_REPORT_1", # folder for report generation
"report_name": "WHITEBOX REPORT",
"report_version_id": 1,
"city": "Moscow",
"model_aim": "Predict if candidate will work for the company",
"model_name": "HR model",
"zakazchik": "Kaggle",
"high_level_department": "Ai Lab",
"ds_name": "Btbpanda",
"target_descr": "Candidate will work for the company",
"non_target_descr": "Candidate will work for the company"}
auto_woe_0.generate_report(report_params, )
AutoWoE - simpler model
[12]:
auto_woe_1 = AutoWoE(interpreted_model=True,
monotonic=True,
max_bin_count=4,
select_type=None,
pearson_th=0.9,
metric_th=.505,
vif_th=10.,
imp_th=0,
th_const=32,
force_single_split=True,
th_nan=0.01,
th_cat=0.005,
metric_tol=1e-4,
cat_alpha=100,
cat_merge_to="to_woe_0",
nan_merge_to="to_woe_0",
imp_type="feature_imp",
regularized_refit=False,
p_val=0.05,
verbose=2
)
auto_woe_1 = ReportDeco(auto_woe_1, )
[13]:
auto_woe_1.fit(train,
target_name="target",
)
[LightGBM] [Info] Number of positive: 3033, number of negative: 9227
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000364 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 518
[LightGBM] [Info] Number of data points in the train set: 12260, number of used features: 12
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.247390 -> initscore=-1.112582
[LightGBM] [Info] Start training from score -1.112582
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[11] val_test's auc: 0.810634
city processing...
city_development_index processing...
gender processing...
relevant_experience processing...
enrolled_university processing...
education_level processing...
major_discipline processing...
experience processing...
company_size processing...
company_type processing...
last_new_job processing...
training_hours processing...
dict_keys(['city', 'city_development_index', 'gender', 'relevant_experience', 'enrolled_university', 'education_level', 'major_discipline', 'experience', 'company_size', 'company_type', 'last_new_job', 'training_hours']) to selector !!!!!
Feature selection...
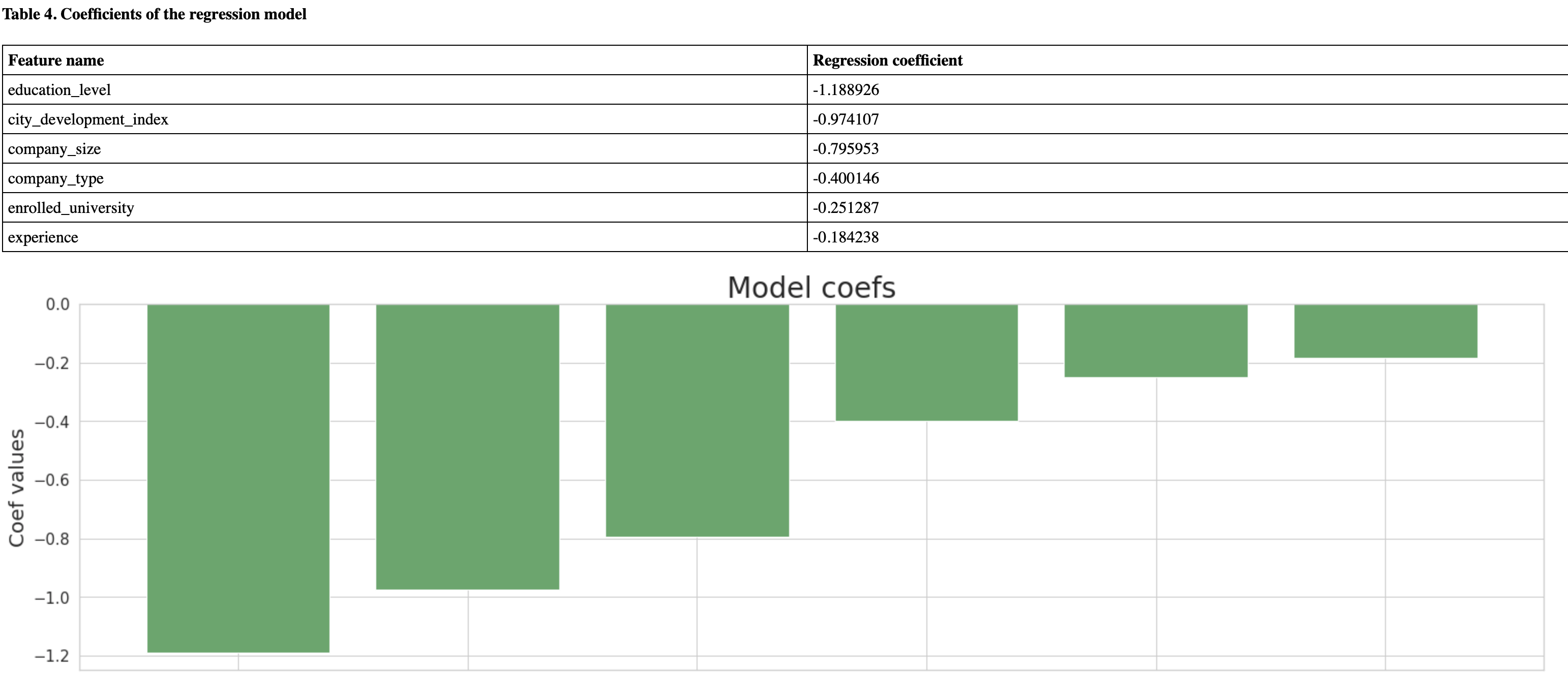
city -0.525685
city_development_index -0.482931
company_size -0.884190
company_type -0.401782
experience -0.272925
enrolled_university -0.231768
education_level -0.673794
major_discipline -1.606442
dtype: float64
[14]:
test_prediction = auto_woe_1.predict_proba(test)
test_prediction
[14]:
array([0.06195668, 0.59982925, 0.03708212, ..., 0.13104366, 0.05378754,
0.0487648 ])
[15]:
roc_auc_score(test['target'].values, test_prediction)
[15]:
0.7991679814815826
[16]:
report_params = {"output_path": "HR_REPORT_2", # folder for report generation
"report_name": "WHITEBOX REPORT",
"report_version_id": 2,
"city": "Moscow",
"model_aim": "Predict if candidate will work for the company",
"model_name": "HR model",
"zakazchik": "Kaggle",
"high_level_department": "Ai Lab",
"ds_name": "Btbpanda",
"target_descr": "Candidate will work for the company",
"non_target_descr": "Candidate will work for the company"}
auto_woe_1.generate_report(report_params, )
WhiteBox preset - like TabularAutoML
[17]:
from lightautoml.automl.presets.whitebox_presets import WhiteBoxPreset
from lightautoml.tasks import Task
[18]:
task = Task('binary')
automl = WhiteBoxPreset(task)
[19]:
train_pred = automl.fit_predict(train.reset_index(drop=True), roles={'target': 'target'})
[LightGBM] [Info] Number of positive: 3033, number of negative: 9227
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000469 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 518
[LightGBM] [Info] Number of data points in the train set: 12260, number of used features: 12
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.247390 -> initscore=-1.112582
[LightGBM] [Info] Start training from score -1.112582
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[17] val_test's auc: 0.805941
[20]:
test_prediction = automl.predict(test).data[:, 0]
[21]:
roc_auc_score(test['target'].values, test_prediction)
[21]:
0.7966626448798652
Serialization
Important note: auto_woe_1 is the ReportDeco object (the report generator object), not AutoWoE itself. To receive the AutoWoE object you can use the auto_woe_1.model.
ReportDeco object usage for inference is not recommended for several reasons:
The report object needs to have the target column because of model quality metrics calculation
Model inference using
ReportDecoobject is slower than the usual one because of the report update procedure
[22]:
joblib.dump(auto_woe_1.model, 'model.pkl')
model = joblib.load('model.pkl')
SQL inference query
[23]:
sql_query = model.get_sql_inference_query('global_temp.TABLE_1')
print(sql_query)
SELECT
1 / (1 + EXP(-(
-1.11
-0.526*WOE_TAB.city
-0.483*WOE_TAB.city_development_index
-0.884*WOE_TAB.company_size
-0.402*WOE_TAB.company_type
-0.273*WOE_TAB.experience
-0.232*WOE_TAB.enrolled_university
-0.674*WOE_TAB.education_level
-1.606*WOE_TAB.major_discipline
))) as PROB,
WOE_TAB.*
FROM
(SELECT
CASE
WHEN (city IS NULL OR LOWER(CAST(city AS VARCHAR(50))) = 'nan') THEN 0
WHEN city IN ('city_100', 'city_102', 'city_103', 'city_116', 'city_149', 'city_159', 'city_160', 'city_45', 'city_46', 'city_64', 'city_71', 'city_73', 'city_83', 'city_99') THEN 0.213
WHEN city IN ('city_104', 'city_114', 'city_136', 'city_138', 'city_16', 'city_173', 'city_23', 'city_28', 'city_36', 'city_50', 'city_57', 'city_61', 'city_65', 'city_67', 'city_75', 'city_97') THEN 1.017
WHEN city IN ('city_11', 'city_21', 'city_74') THEN -1.455
ELSE -0.209
END AS city,
CASE
WHEN (city_development_index IS NULL OR city_development_index = 'NaN') THEN 0
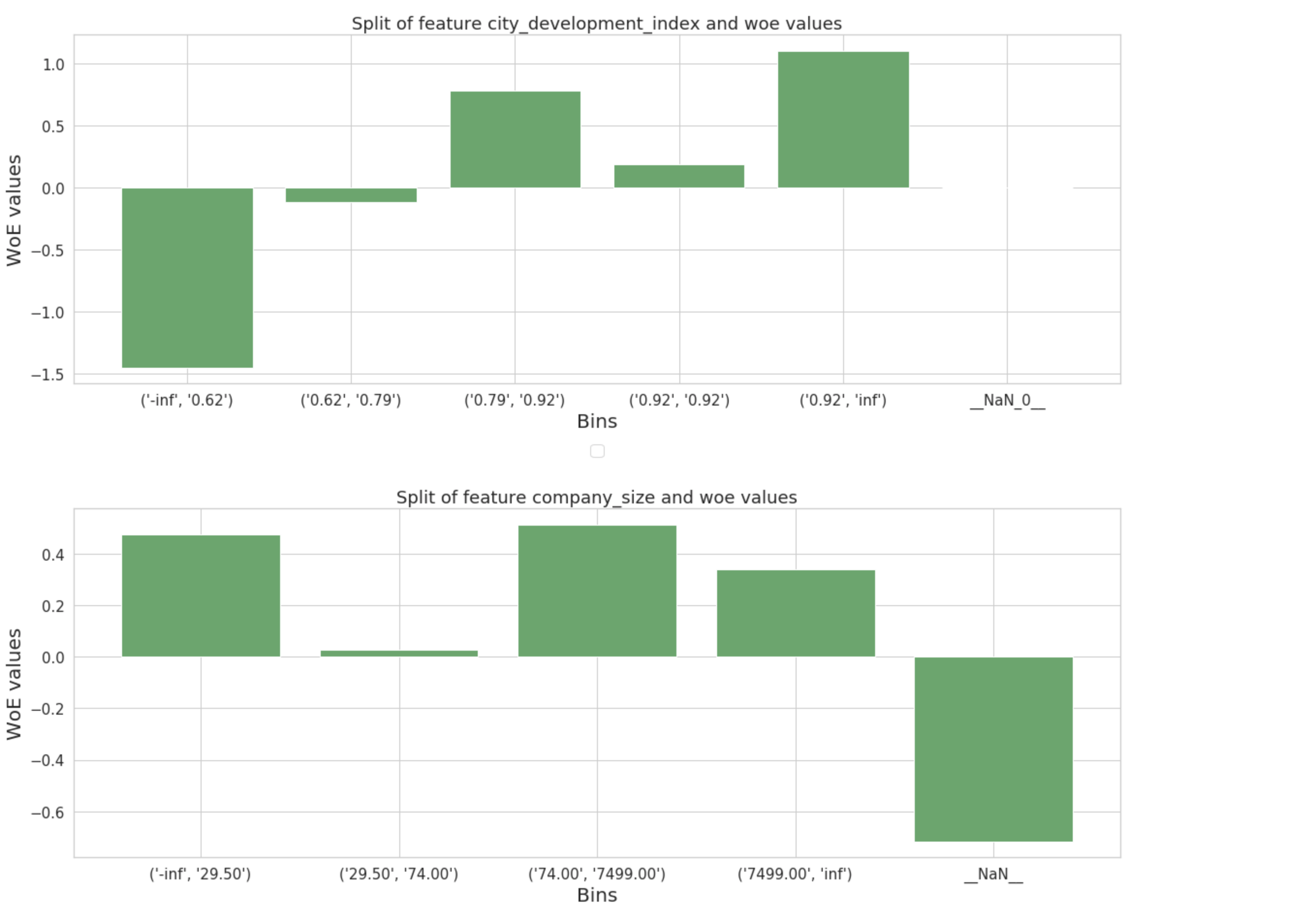
WHEN city_development_index <= 0.6245 THEN -1.454
WHEN city_development_index <= 0.7915 THEN -0.121
WHEN city_development_index <= 0.9235 THEN 0.461
ELSE 1.101
END AS city_development_index,
CASE
WHEN (company_size IS NULL OR company_size = 'NaN') THEN -0.717
WHEN company_size <= 74.0 THEN 0.221
ELSE 0.467
END AS company_size,
CASE
WHEN (company_type IS NULL OR LOWER(CAST(company_type AS VARCHAR(50))) = 'nan') THEN -0.64
WHEN company_type IN ('Early Stage Startup', 'NGO', 'Other', 'Public Sector') THEN 0.164
WHEN company_type == 'Funded Startup' THEN 0.737
WHEN company_type == 'Pvt Ltd' THEN 0.398
ELSE 0
END AS company_type,
CASE
WHEN (experience IS NULL OR experience = 'NaN') THEN 0
WHEN experience <= 1.5 THEN -0.811
WHEN experience <= 7.5 THEN -0.319
WHEN experience <= 11.5 THEN 0.119
ELSE 0.533
END AS experience,
CASE
WHEN (enrolled_university IS NULL OR LOWER(CAST(enrolled_university AS VARCHAR(50))) = 'nan') THEN -0.327
WHEN enrolled_university == 'Full time course' THEN -0.614
WHEN enrolled_university == 'Part time course' THEN 0.026
WHEN enrolled_university == 'no_enrollment' THEN 0.208
ELSE 0
END AS enrolled_university,
CASE
WHEN (education_level IS NULL OR LOWER(CAST(education_level AS VARCHAR(50))) = 'nan') THEN 0.21
WHEN education_level == 'Graduate' THEN -0.166
WHEN education_level == 'High School' THEN 0.34
WHEN education_level == 'Masters' THEN 0.21
WHEN education_level IN ('Phd', 'Primary School') THEN 0.704
ELSE 0
END AS education_level,
CASE
WHEN (major_discipline IS NULL OR LOWER(CAST(major_discipline AS VARCHAR(50))) = 'nan') THEN 0.333
WHEN major_discipline == 'Arts' THEN 0.199
WHEN major_discipline IN ('Business Degree', 'No Major', 'Other', 'STEM') THEN -0.071
WHEN major_discipline == 'Humanities' THEN 0.333
ELSE 0
END AS major_discipline
FROM global_temp.TABLE_1) as WOE_TAB
Check the SQL query by PySpark
[ ]:
from pyspark.sql import SparkSession
[ ]:
spark = SparkSession.builder \
.master("local[2]") \
.appName("spark-course") \
.config("spark.driver.memory", "512m") \
.getOrCreate()
sc = spark.sparkContext
[24]:
spark_df = spark.read.csv("jobs_train.csv", header=True)
spark_df.createGlobalTempView("TABLE_1")
[25]:
res = spark.sql(sql_query).toPandas()
[ ]:
res
[27]:
sc.stop()
[ ]:
full_prediction = model.predict_proba(data)
full_prediction
[ ]:
(res['PROB'] - full_prediction).abs().max()